Why AI Networks Are Being Redefined
With the rapid development of artificial intelligence, particularly large language models (LLMs), the scale of AI training has exploded. From early models with hundreds of millions of parameters to today’s giants with trillions or even tens of trillions of parameters, distributed training has become the mainstream approach. This requires thousands—or even tens of thousands—of GPUs to collaborate closely, making the network the bottleneck of overall system performance.
Traditional data center networks can no longer meet these demands. In their place, two high-performance interconnect technologies supporting RDMA (Remote Direct Memory Access) have emerged: InfiniBand and RoCE (RDMA over Converged Ethernet). Both achieve microsecond-level latency and high bandwidth, but with different design philosophies, they are reshaping the landscape of AI data center networks. In 2025, RoCE is rapidly rising due to its cost advantages and flexibility, while IB continues to dominate in scenarios requiring extreme performance.
InfiniBand and RoCE are currently the two mainstream high-performance interconnect technologies for AI data centers. Both support RDMA, delivering low latency, high bandwidth, and low CPU overhead—far superior to traditional TCP/IP. However, in AI training clusters (such as large-scale GPU distributed training), each has its own strengths.
Introduction to InfiniBand Networks
InfiniBand (abbreviated as IB, literally translated as “Infinite Bandwidth”) is a high-speed network interconnect standard specifically designed for high-performance computing (HPC), data centers, and artificial intelligence (AI) clusters. It features extremely high throughput and ultra-low latency, primarily used for data interconnection between servers, GPUs, and storage systems. It supports Remote Direct Memory Access (RDMA), enabling direct data transfer between memories without CPU involvement, significantly reducing latency and CPU load.
InfiniBand was originally developed to address the bottlenecks of traditional Ethernet in terms of low latency, determinism, and large-scale scalability. With the rise of large-scale AI model training and GPU clusters, InfiniBand has gradually become one of the most important network architectures in high-performance AI data centers.
At the network level, InfiniBand employs a credit-based flow control mechanism that fundamentally prevents packet loss and retransmissions caused by link congestion. At the same time, critical functions such as congestion control and scheduling are primarily handled by hardware, enabling it to maintain low latency and minimal jitter even under high load and large-scale parallel communication scenarios. These characteristics make InfiniBand particularly well-suited for high-frequency communication patterns in AI training, such as All-Reduce operations.
However, from an engineering perspective, InfiniBand also has certain limitations. It is a proprietary network that is difficult to deeply integrate with traditional Ethernet services, typically requiring deployment as an independent fabric. Additionally, its hardware and ecosystem are relatively concentrated, resulting in higher overall costs compared to standard Ethernet solutions. In small- to medium-scale AI clusters, these investments may not translate into significant performance gains.
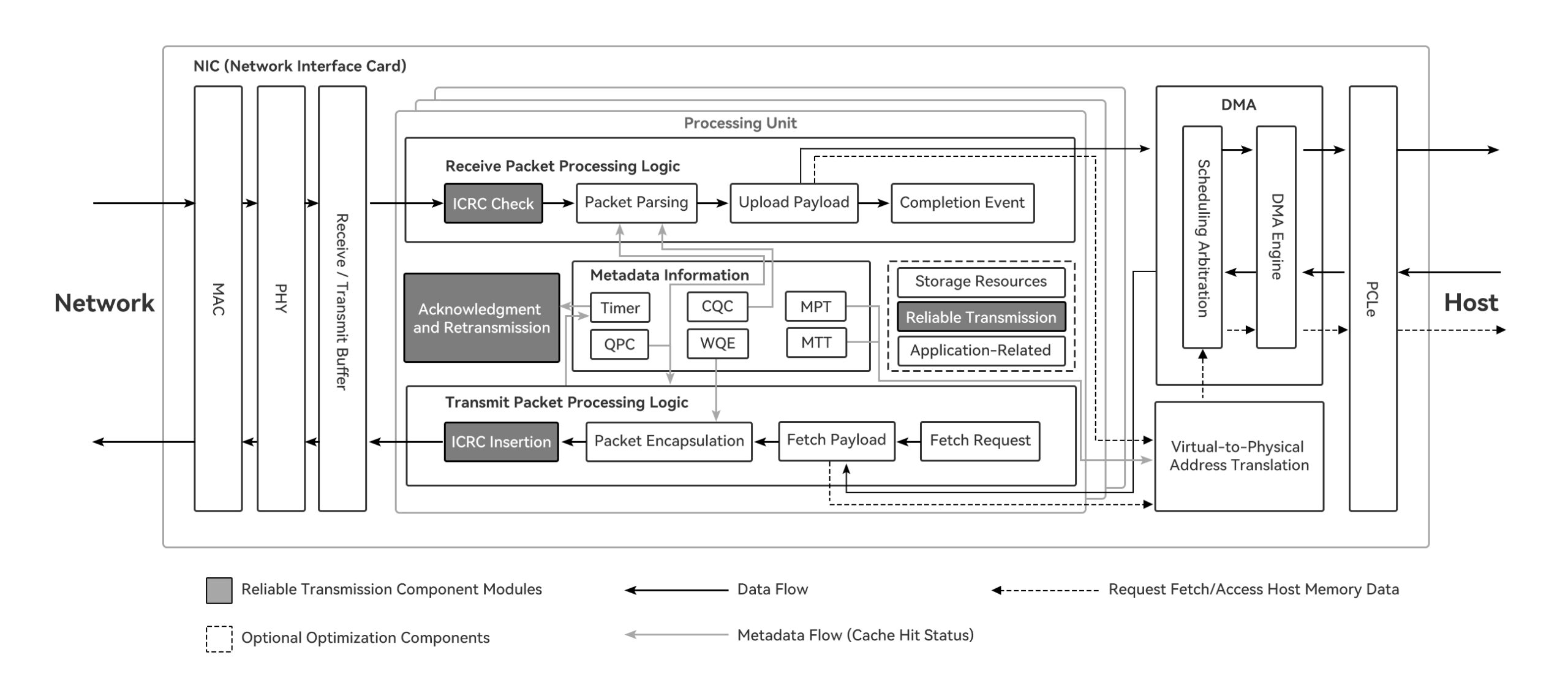
Figure 1 RDMA Architecture Diagram
Introduction to RoCE Networks
RoCE (RDMA over Converged Ethernet) is a network technology that implements RDMA capabilities on top of Ethernet. It aims to introduce low-latency, high-bandwidth interconnect performance while preserving the openness and universality of Ethernet. Unlike InfiniBand, RoCE is not an independent network architecture but rather an RDMA extension built on standard Ethernet.
RoCE bypasses the traditional TCP/IP protocol stack to enable direct memory-to-memory communication between nodes, thereby reducing CPU overhead and shortening communication paths. In AI data centers, RoCE is commonly used to support parameter synchronization and high-speed data exchange between GPUs, making it particularly suitable for environments where Ethernet is already the core architecture.
At the implementation level, RoCE relies on constructing a near-lossless network environment on the Ethernet side. This typically requires the use of PFC (Priority-based Flow Control), ECN (Explicit Congestion Notification), and congestion feedback-based control algorithms to minimize packet loss. As a result, RoCE’s performance depends not only on RDMA itself but also heavily on network device configuration and overall architecture design.
Overall, RoCE represents a balanced solution between performance and versatility. It cannot fully match InfiniBand’s deterministic performance at extreme scales, but with proper tuning and controlled cluster sizes, it offers high cost-effectiveness in AI inference and small- to medium-scale training scenarios, while maintaining excellent compatibility with existing Ethernet ecosystems.
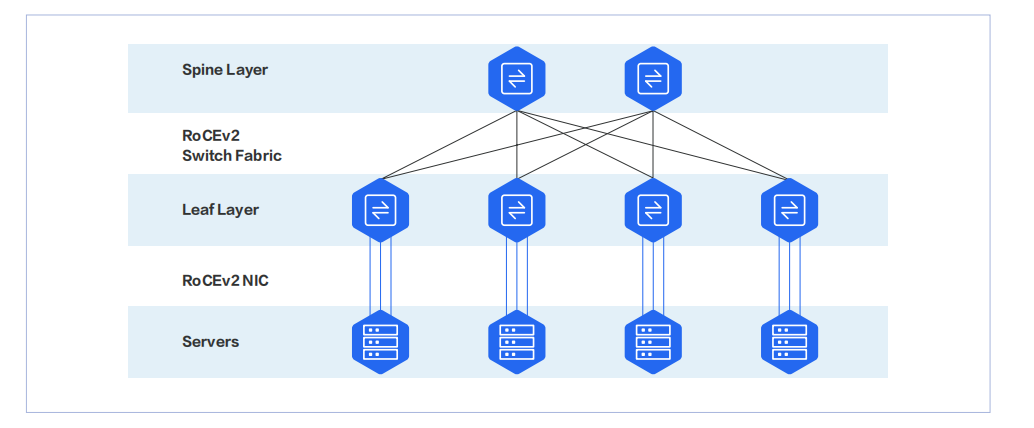
Figure 2 RoCE Network Architecture Diagram
InfiniBand vs. RoCE: Differences in Design Philosophies
From a design philosophy perspective, InfiniBand and RoCE represent two distinct paths in network evolution. InfiniBand is a dedicated interconnect technology born for high-performance parallel computing. It emphasizes native RDMA, lossless networking, and hardware-level congestion control, pursuing low latency and high determinism even at massive scale. This gives it a natural advantage in ultra-large-scale AI training and HPC scenarios.
In contrast, RoCE introduces RDMA capabilities on top of standard Ethernet, seeking a balance between performance and versatility. It can reuse existing Ethernet infrastructure and ecosystems, lowering deployment barriers and overall costs. However, its performance is highly dependent on network configuration and tuning expertise. In well-controlled and properly designed environments, RoCE can deliver communication efficiency close to that of dedicated interconnects, but at larger scales, network stability and predictability become more challenging.
Therefore, the differences between the two go beyond a simple comparison of performance levels—they reflect an engineering trade-off between dedicated interconnects and enhanced general-purpose networks. Understanding these fundamental differences in design philosophy helps make more rational network choices for specific AI scenarios.
InfiniBand vs. RoCE
| Category |
InfiniBand |
RoCE (RoCE v2) |
| Network Type |
Proprietary fabric |
Standard Ethernet |
| Transport Protocol |
Native InfiniBand |
RDMA over Ethernet (UDP/IP) |
| Latency |
Ultra-low (sub-microsecond) |
Low (slightly higher than IB) |
| Bandwidth Efficiency |
Extremely high |
High |
| Lossless Behavior |
Native lossless |
Requires PFC / ECN |
| Congestion Control |
Built-in |
DCQCN / ECN-based |
| Network Complexity |
Lower (closed ecosystem) |
Higher (requires tuning) |
| Ecosystem Maturity |
HPC & AI focused |
Cloud & data center mainstream |
| Hardware Cost |
Higher |
More cost-effective |
| Typical Speeds |
200G / 400G (HDR / NDR) |
100G / 200G / 400G / 800G |
| Vendor Landscape |
NVIDIA (Mellanox) |
NVIDIA, Broadcom, Intel |
| Scalability |
Excellent for very large clusters |
Excellent for flexible scaling |
| Deployment Model |
Dedicated AI/HPC fabrics |
Converged data center networks |
Precisely because InfiniBand and RoCE differ fundamentally in their design goals and engineering trade-offs, they are suited to different use cases in real-world AI data center deployments.
How to Choose for AI Workloads?

In large-scale AI training environments, network performance has a direct impact on training efficiency and overall cluster scalability. If your primary objective is to minimize training time—especially in very large GPU clusters with more than 1,000 GPUs—InfiniBand remains the preferred choice. Its native lossless design, ultra-low and highly consistent latency, and deep optimization for collective communication operations such as All-Reduce make it particularly well suited for communication-intensive training workloads.
In addition, InfiniBand is tightly integrated with the NVIDIA GPU, NIC, and switch ecosystem, and has been extensively validated in reference architectures such as DGX and SuperPOD, making it ideal for performance-driven AI training environments with sufficient network budgets.
By contrast, RoCE is better aligned with AI deployments that prioritize cost efficiency and network convergence. For enterprises and cloud providers looking to build or expand AI infrastructure on top of existing Ethernet networks, RoCE enables RDMA acceleration without introducing a separate, proprietary fabric. It allows AI training, inference, storage, and general-purpose workloads to coexist on a unified network, which is especially attractive for small to mid-sized GPU clusters and mixed-use data centers.
Moreover, as 400G and 800G Ethernet continue to mature, the performance gap between RoCE and InfiniBand is steadily narrowing, while Ethernet’s open ecosystem offers greater flexibility for long-term scaling and upgrades.
In summary, InfiniBand is optimized for maximum performance, whereas RoCE emphasizes scalability, cost control, and architectural flexibility. In practice, many modern AI data centers deploy both: InfiniBand for core training clusters, and RoCE-based Ethernet for edge training, inference, and converged workloads—achieving a balanced approach between performance and total cost of ownership.
Which Is More Suitable for AI Data Center Networks?

In simple terms, InfiniBand and RoCE are not in a “winner-takes-all” relationship; instead, each is suited to different types of AI scenarios.
InfiniBand: Born for Ultimate Performance
If your primary goal is to minimize training time as much as possible, InfiniBand remains the most reliable choice—especially for ultra-large-scale, tightly coupled AI training clusters. In setups involving thousands or even tens of thousands of GPUs that require frequent parameter synchronization for large model training, every bit of network latency and jitter gets magnified.
InfiniBand’s strengths lie in its extremely low and stable latency, allowing GPUs to maintain high utilization for extended periods and achieving higher Model Flops Utilization (MFU). When training models with trillions of parameters, this advantage often translates directly into shorter training cycles.
Of course, this performance comes at a cost: higher expenses, a relatively closed ecosystem, and typically a commitment to the NVIDIA stack. For projects with ample budgets and a priority on performance, InfiniBand is still regarded as the “gold standard” by many leading AI clusters.
RoCE: A More Practical and Flexible Choice
In contrast, RoCE is more like a solution designed for “scaled AI.” It is based on Ethernet and can evolve on top of existing network infrastructure, making it particularly suitable for cost-sensitive AI data centers that require flexible expansion—such as medium- to large-scale training clusters, AI inference deployments, and cloud-based or hybrid environments.
When network design and tuning are properly implemented, RoCE’s actual performance is now very close to that of InfiniBand. In many real-world tests, the training speed difference between the two is not significant, but RoCE offers greater advantages in cost, device selection, and compatibility, while also integrating more easily with existing data center networks.
By 2025, with the advancement of the Ultra Ethernet Consortium (UEC) and the ongoing optimization of Ethernet chips like those from Broadcom’s Tomahawk series, RoCE’s cost-effectiveness has further improved. An increasing number of enterprises are adopting hybrid architectures: using InfiniBand for core training, and RoCE for peripheral training, inference, and general-purpose services.
Conclusion
Both technologies have their respective strengths and the choice depends on specific needs. If the focus is on cutting-edge large-model training with performance as the top priority, InfiniBand is superior. If the goal is to build cost-effective, rapidly scalable AI infrastructure, RoCE is more suitable (and current trends are also leaning toward RoCE).
It is recommended to evaluate based on cluster scale, workload (training vs. inference), and budget, and consider heterogeneous networks when necessary.
Post Views: 5,154














