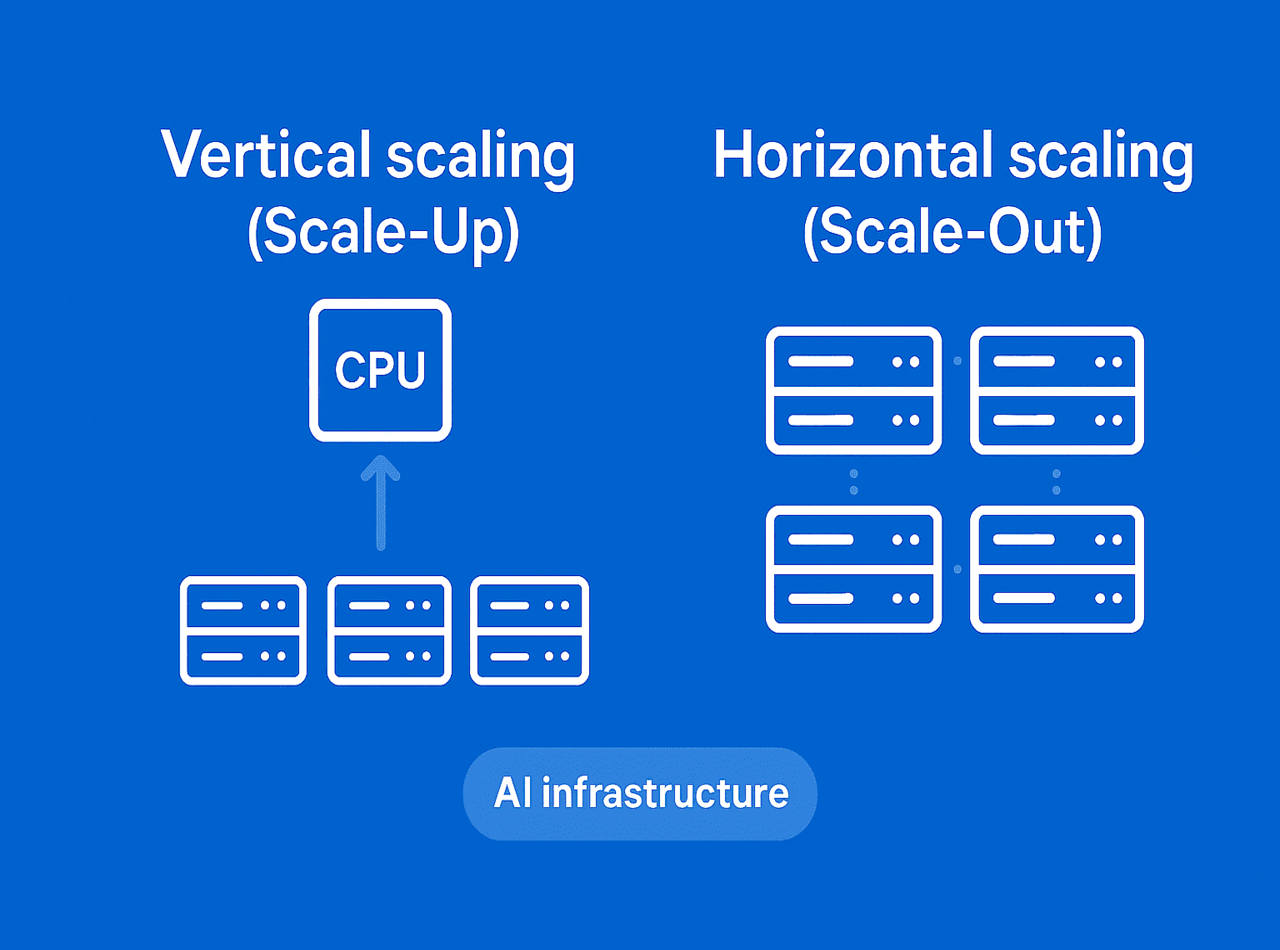
The development of artificial intelligence relies on three fundamental elements: computing power, algorithms, and data. Among them, computing power serves as the driving force behind AI innovation. As model sizes continue to grow, the demand for computation increases exponentially. Today’s AI workloads are mainly powered by parallel computing chips such as GPUs, NPUs, and TPUs, which are combined to form AI servers and large-scale computing clusters for training and inference tasks.
A single AI server, typically equipped with eight accelerator cards, is limited by thermal and power constraints, making it difficult to support large-scale model training. To handle models with hundreds of billions or even trillions of parameters, computing capacity must scale from individual servers to massive AI clusters.
By adopting both vertical scaling (Scale Up) to enhance single-node performance and horizontal scaling (Scale Out) to increase the number of nodes, AI infrastructure can continuously expand its computing capability—evolving from single servers to large-scale clusters and eventually to intelligent computing centers. This expansion provides the solid foundation needed for generative AI, large model training, and enterprise-level intelligent applications.
Understanding Scale-Up and Scale-Out
Scale-Up (Vertical Scaling) and Scale-Out (Horizontal Scaling) are concepts rooted in the evolution of computer architecture, designed to address the ever-increasing demands for performance, capacity, and efficiency. In the AI-driven era, these two scaling approaches are evolving in a complementary way to meet the growing computational requirements of data processing, AI training, and cloud computing.
Scale-Up enhances system capability by increasing the resources of a single node, while Scale-Out distributes workloads by adding more nodes to the system. The two architectures differ significantly in design logic, application scenarios, and scalability challenges. Particularly in the age of AI, as model sizes grow exponentially—from GPT-3 to even larger models—Scale-Up and Scale-Out are being redefined as interdependent strategies for building high-performance computing infrastructure.
Scale Up
Scale Up (Vertical Scaling): Also known as “scaling up,” it enhances performance by upgrading the hardware resources of a single server or node (such as adding CPU cores, memory, GPUs, or storage), making the individual node or device more powerful. For example, upgrading a server’s CPU from 4 cores to 64 cores, or adding more GPUs to handle larger workloads.
Features:
1.High bandwidth, low latency, suitable for high-frequency interaction tasks (such as tensor parallelism in AI model training).
2.Hardware is tightly coupled, with high communication efficiency, but limited in scalability.
3.Typically used to build high-performance “super nodes,” such as NVIDIA’s NVL72 super node.
Application Scenarios: Suitable for scenarios with extremely high requirements for computational density and communication efficiency, such as AI large model training, high-performance computing (HPC), etc.
Image Source: NVIDIA Official Website
Scale Out
Scale Out (Horizontal Scaling): Also known as “scaling out,” it expands the system by adding more independent nodes (such as servers, virtual machines, or containers) and uses load balancers to distribute the workload. For example, in cloud computing, adding hundreds of servers to form a distributed cluster.
Features:
1. High flexibility, allowing on-demand expansion of node quantity, suitable for large-scale data processing and distributed tasks.
2. Relies on general networks (such as Ethernet or InfiniBand) for node interconnection, with relatively higher latency.
3. Applicable to loosely coupled tasks, such as data parallelism and pipeline parallelism.
Application Scenarios: Suitable for scenarios requiring elastic expansion, such as cloud computing, big data processing, distributed storage, etc.
Main Differences Between Scale Up and Scale Out
The primary difference between Scale Up (vertical scaling) and Scale Out (horizontal scaling) lies in the interconnection speed between AI chips. Scale Up focuses on high-speed intra-node connectivity, offering higher performance and lower latency, while Scale Out relies on inter-node distributed networking, emphasizing scalability and flexibility.
Connection Speed and Performance Comparison
Scale Up (Intra-node Interconnect):
Delivers higher connection speeds, lower latency, and stronger overall performance.
Supports tens of terabits per second (10 Tbps) of interconnect bandwidth among hundreds of GPUs.
Requires ultra-low latency, typically in the hundreds of nanoseconds (100 ns = 0.1 μs).
Ideal for high-frequency communication and latency-sensitive workloads, such as tensor parallelism (TP) in AI model training.
Scale Out (Inter-node Interconnect):
Primarily uses Infiniband (IB) and RoCEv2 technologies, both based on RDMA (Remote Direct Memory Access).
Provides Tbps-level bandwidth with strong load-balancing capability, though lower than Scale Up’s 10 Tbps.
Latency typically reaches around 10 microseconds.
Offers higher speed and lower latency than traditional Ethernet, yet still cannot match the performance of Scale Up.
Application Scenarios and Parallel Computing
Parallelism in AI Training:
Includes Tensor Parallelism (TP), Expert Parallelism (EP), Pipeline Parallelism (PP), and Data Parallelism (DP).
Scale Up focuses on maximizing single-node performance, making it ideal for latency-sensitive and high-frequency communication tasks, such as parameter exchange and data synchronization.
Scale Out emphasizes flexibility and scalability, making it well-suited for large-scale distributed workloads.
Combined Usage:
In practical AI training systems, Scale Up and Scale Out are often used together — Scale Up handles intra-node GPU interconnects, while Scale Out manages inter-node cluster expansion, achieving end-to-end system optimization.
Supernode — The Optimal Form of Scale Up
Definition and Advantages:
A supernode connects multiple GPUs through high-speed internal buses, enabling efficient parallel computing.
It accelerates parameter exchange and data synchronization among GPUs, significantly shortening large-model training cycles.
Supports memory semantic capabilities, allowing GPUs to directly access each other’s memory — a feature unavailable in Scale Out architectures.
From Networking and Operations Perspective:
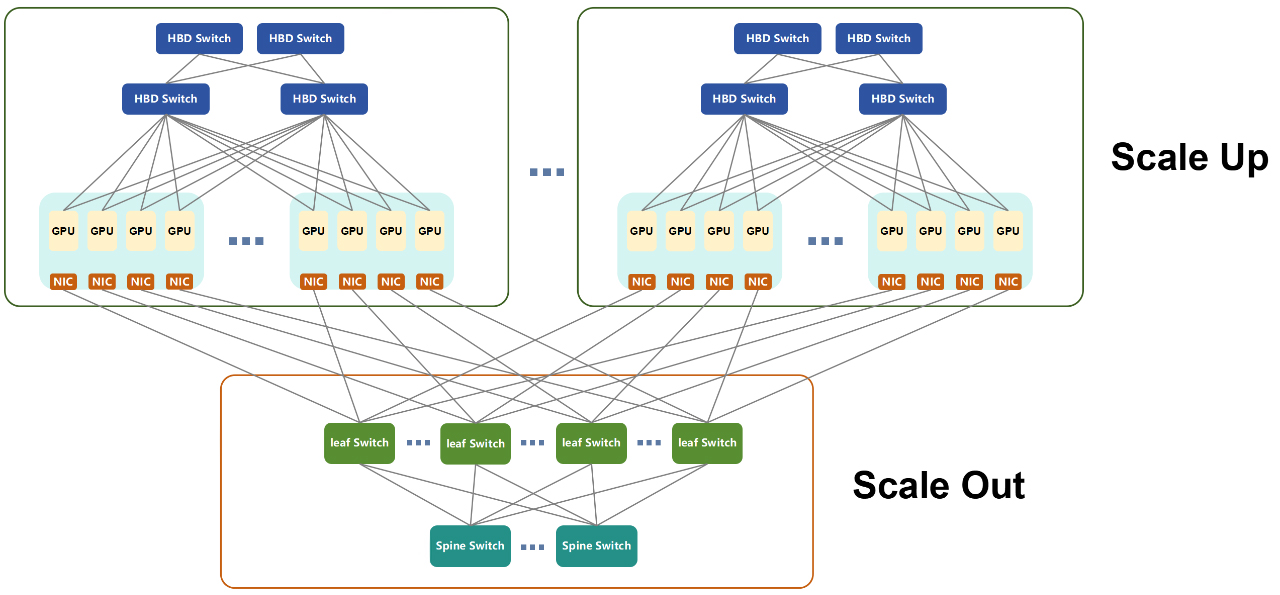
The larger the HBD (High Bandwidth Domain) of a supernode and the more GPUs it integrates via Scale Up, the simpler the Scale Out network architecture becomes.
This greatly reduces networking complexity and provides notable operational advantages in deployment and maintenance.
Scale-Up & Scale-Out Network Architecture Diagram
Summary
Scale Up and Scale Out represent a balance between performance and cost: Scale Up delivers extreme performance but has limited scalability. Scale Out offers virtually unlimited expansion but its performance is constrained by network bandwidth and latency.
As technology advances, larger-scale supernodes will emerge, and the boundary between Scale Up and Scale Out will become increasingly blurred, paving the way for more integrated and efficient AI computing architectures.
Applications in AI and Computing Systems
In the field of AI, Scale Up and Scale Out are driving a fundamental reconstruction of infrastructure to support large-scale model training and inference.
Role of Scale Up in AI:
Scale Up focuses on building “supernodes”, where thousands of GPUs are integrated into a high-density system to support strong scaling. This requires advanced interconnect technologies such as silicon photonics and Co-Packaged Optics (CPO) to overcome bandwidth bottlenecks.
For example, NVIDIA’s DGX systems use Scale Up to enable multi-GPU collaboration within a single machine, accelerating AI training but facing power and thermal management constraints.
By 2028, Scale Up networks are expected to emphasize dense, reliable intra-node connections, driving the optical communication industry toward chip-level photonic integration.
Role of Scale Out in AI:
Scale Out supports large-scale distributed clusters, connecting tens of thousands of GPUs across data centers to achieve weak scaling. It relies on high-bandwidth networks such as InfiniBand or Ethernet, making it suitable for cloud AI services like Azure and AWS.
For instance, Meta’s AI clusters leverage Scale Out to scale horizontally and process massive datasets, though they face challenges in network heterogeneity and flexibility.
Scale Out architectures offer greater flexibility and can adapt to traditional hierarchical networks, but require optimization to handle predictive AI workloads efficiently.
Hybrid Approach — Scale-Across:
Modern AI systems increasingly combine both approaches, forming “Scale-Across” or hybrid architectures.
For example, Huawei’s AI Fabric integrates supernode (Scale Up) and cluster expansion (Scale Out) through mathematical optimization, overcoming power and spatial constraints.
This hybrid evolution redefines AI networking, shifting from single-direction scaling toward sustainable, full-stack optimization.
The continuous advancement of artificial intelligence depends on powerful computing capabilities, which are evolving from single nodes to supernodes and from clusters to intelligent computing centers. Scale-Up (vertical scaling) enhances single-node performance to deliver extreme computation and ultra-low latency, while Scale-Out (horizontal scaling) enables flexible and scalable distributed architectures for large-scale AI training and cloud services.
These two approaches are not mutually exclusive but complementary—Scale-Up forms the high-performance computing core, and Scale-Out enables large-scale resource coordination. With the emergence of technologies such as silicon photonics and Co-Packaged Optics (CPO), AI computing infrastructure is moving toward hybrid “Scale-Across” architectures, unifying performance and scalability to drive the next generation of intelligent, full-stack optimized computing systems.
As a professional provider of AI networking solutions, AscentOptics leverages its strong technical expertise and premium product portfolio—including optical transceivers, AOC/DAC cables and switches—to help customers build high-performance and scalable AI computing infrastructures.