Introduction
Training massive language models such as GPT-4 requires petabytes of data and places enormous demands on inter-process communication across thousands of GPUs. In one real-world case, a large AI research organization discovered that its GPU cluster was operating at no more than 60% utilization. This raised a critical question: should they invest in better analytics frameworks, or were they effectively wasting millions of dollars in compute resources due to network bottlenecks?
Similar situations are occurring in data centers worldwide. AI workloads push network architectures to their limits, with traffic patterns shifting from traditional north-south flows to highly intensive east-west communication between compute nodes. As a result, QSFP-DD has emerged as a key enabler of next-generation AI data center infrastructure, helping architects scale bandwidth efficiently.
The bandwidth requirements for large-scale AI training and inference are increasingly dependent on high-speed optical transceivers, particularly those based on the QSFP-DD form factor. This guide explores key technical features for GPU clusters, examines spine-leaf architectures for distributed AI applications, and evaluates whether QSFP-DD or OSFP is better suited for future AI data centers.
Planning AI cluster networking? Explore our QSFP-DD transceiver solutions for high-speed GPU interconnects →
Why AI Data Centers Demand QSFP-DD Technology
The AI Bandwidth Explosion
The deployment of contemporary AI tasks has changed the paradigms of data centers. During deep learning processes, it is often necessary to synchronize parameters within a model stored across many hundreds or even thousands of GPUs; subsequently, the bandwidth requirements of AI models exceed those of any traditional cloud computing structure.
A typical GPT-class model training run might involve:
- •Parameter server communication: 3-5 Tb/s aggregate bandwidth for gradient synchronization
- •All-reduce operations: Collective operations requiring simultaneous high-speed access to all nodes
- •Checkpoint storage: Rapid writes to distributed storage systems during training pauses
- •Data pipeline feeding: Continuous high-bandwidth delivery of training data to compute nodes
Industry estimates suggest that a standard AI GPU rack requires approximately thirty-six times more fiber connectivity than an average CPU rack in any conventional data center. If we consider a large-scale AI training center with 10,000 GPUs in operation for training purposes, more than 8 million miles of optical fiber may be required to enable effective network interconnections between compute nodes within such an AI data center.
GPU Utilization Depends on Interconnect Speed
This is one of the most important lessons learned the hard way by most infrastructure teams—that GPU utilization scales linearly with data transfer rates. As powerful as these AI applications and expensive accelerators may be, huge AI systems can still leave expensive hardware entirely unused and idle due to network latencies.
It was then that Chen Wei, from a cloud provider located in Shanghai, began to derive hypotheses from the growing pains of their first 1,024-GPU training cluster configuration in late 2023. At that time, the cluster was connected via 100G links between the computing nodes. Upon exploration of working statistics, it revealed that GPU utilization was a lukewarm 65%. This changed after the upgrade to 400G QSFP-DD links between leaf-spine connections, showing an average performance of 91%. In the simplest terms, the infrastructure upgrade resulted in 40% more ROI from the attached compute investment.
QSFP-DD Density Advantages for AI Clusters
QSFP-DD (Quad Small Form-factor Pluggable Double Density) delivers the bandwidth density AI clusters require without sacrificing port count. By doubling electrical lanes from 4 to 8 within the familiar QSFP footprint, QSFP-DD achieves:
- •400G: 8 lanes × 50G PAM4 signaling
- •800G: 8 lanes × 100G PAM4 signaling
- •Port density: Up to 36 ports per 1U switch (14.4 Tb/s per rack unit)
This density matters enormously in AI clusters where rack space translates directly to compute capacity. Every rack unit consumed by networking equipment reduces available space for GPU servers.
Need high-density optical connectivity for AI infrastructure? View our QSFP-DD 400G/800G module specifications →
QSFP-DD Technical Specifications for AI Workloads
From 400G to 800G: Scaling with AI Demands
The transition from 400G to 800G QSFP-DD modules reflects the accelerating bandwidth requirements of AI training workloads. Understanding the technical specifications helps infrastructure teams plan appropriate upgrades.

| Specification |
QSFP-DD 400G |
QSFP-DD 800G |
| Lane Configuration |
8 × 50G PAM4 |
8 × 100G PAM4 |
| Aggregate Rate |
400 Gbps |
800 Gbps |
| Power Consumption |
10-14W typical |
14-18W typical |
| Thermal Load |
Moderate |
Higher (but manageable) |
| Management Interface |
CMIS 4.0+ |
CMIS 5.0+ |
| Backward Compatibility |
QSFP28, QSFP56 |
QSFP-DD 400G, QSFP28 |
The PAM4 transmission (Pulse Amplitude Modulation 4-level) allows for the encoding of 2 bits per symbol per lane, hence doubling the efficiency compared to NRZ. However, it requires additional complexity in signal processing as well as Forward Error Correction (FEC) to support PAM4 performance.
QSFP-DD Module Types for AI Deployments
AI data centers deploy different QSFP-DD variants depending on distance requirements and network topology:
SR8 (Short Reach)
- •Distance: 100m (OM4), 150m (OM5)
- •Fiber: Multimode
- •Application: Intra-rack GPU connections, top-of-rack to server
- •Power: ~12W
DR8 (Data Center Reach)
- •Distance: 500m
- •Fiber: Single-mode
- •Application: Leaf-to-spine fabric connections
- •Power: ~14W

2×FR4 (Fiber Reach)
- •Distance: 2km
- •Fiber: Single-mode
- •Application: Data center interconnect, campus networks
- •Power: ~16W
2×LR4 (Long Range)
- •Distance: 10km
- •Fiber: Single-mode
- •Application: Metro networks, regional DCI
- •Power: ~18W
For AI training clusters, SR8 and DR8 modules handle the majority of connections. The 2×FR4 and 2×LR4 variants become relevant when distributing AI workloads across geographically separated facilities.
Power and Thermal Considerations in AI Environments
Power consumption represents a critical constraint in AI data center design. A fully populated 32-port 800G line card generates significant thermal load:
- •32 ports × 17W per module = 544W transceiver power alone
- •Plus switch ASIC power: 300-500W
- •Total line card power: 850W-1,000W+
- •With cooling overhead (PUE 1.3): 1,100W-1,300W thermal load per card
The majority of challenges arise from 800G implementations at the rack level, which can strain cooling systems. A standard 42U rack filled with switches supporting 800G and GPU servers can consume roughly 40-60 kilowatts of power; therefore, advanced thermal management or even liquid cooling may need to be considered.
However, some Linear Pluggable Optics (LPO) variants can further reduce power consumption to 4-10W because the DSP chip is not needed, though this comes with trade-offs in interoperability (limited to specific host ASICs). In homogeneous AI data centers where equipment is standardized, LPO QSFP-DD optics can bring significant power savings.
Concerned about power budgets for AI networking? Contact our engineers for thermal planning assistance →
Architecture: QSFP-DD in AI Data Center Networks
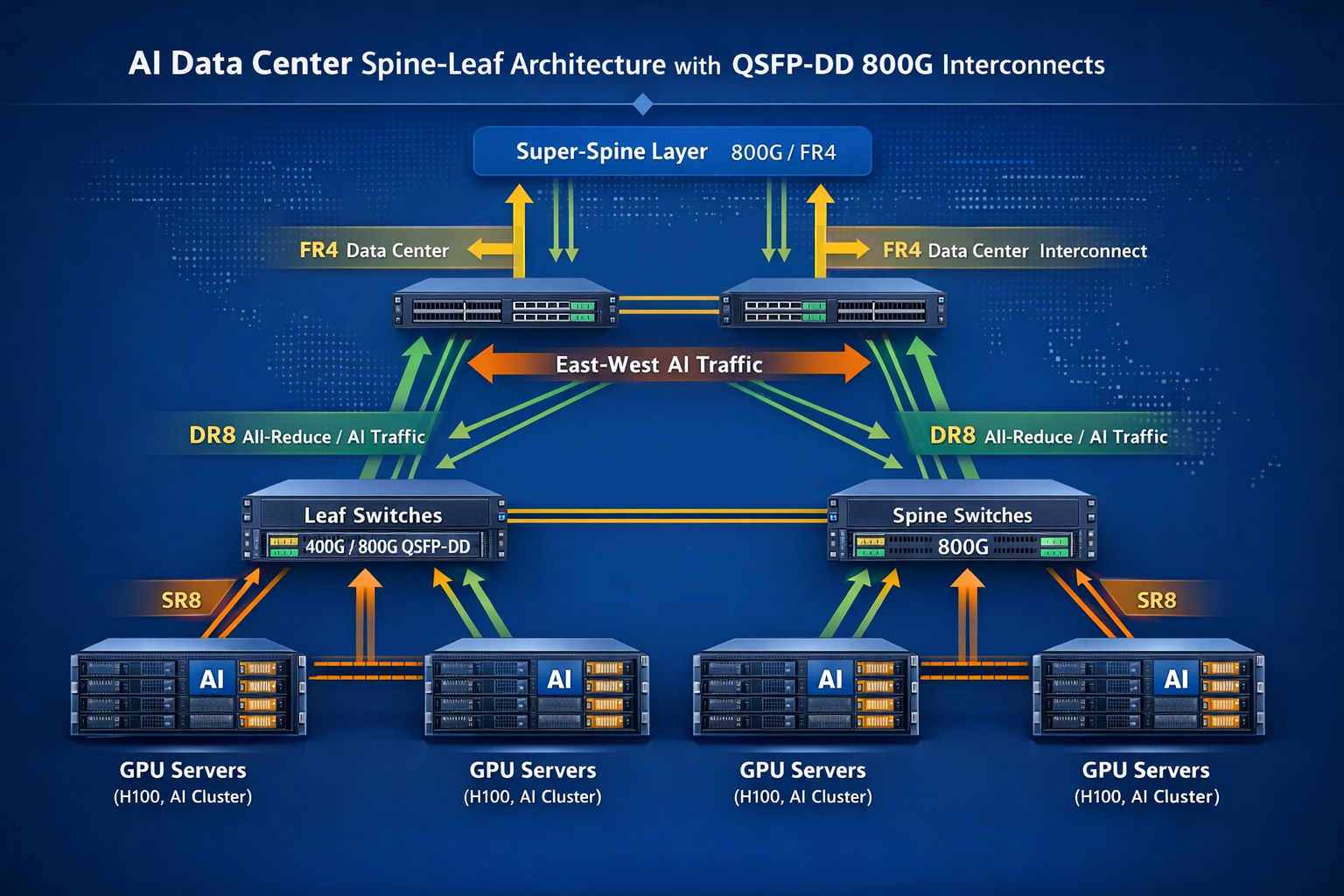
Spine-Leaf Design for GPU Clusters
Modern AI data centers predominantly use Clos (spine-leaf) topologies to provide non-blocking bandwidth between any two GPU nodes. QSFP-DD modules enable these architectures at 400G and 800G speeds.
A typical three-tier AI network architecture includes:
Leaf Layer (Top-of-Rack)
- •32-48 × 400G/800G downlinks to GPU servers
- •8-16 × 800G uplinks to spine switches
- •QSFP-DD SR8 for server connections, DR8 for spine uplinks
Spine Layer
- •32-64 × 800G ports connecting to leaf switches
- •QSFP-DD DR8 or 2×FR4 for interconnection
- •Provides full bisection bandwidth for east-west traffic
Super-Spine Layer (for large clusters)
- •128+ × 800G/1.6T ports
- •QSFP-DD 800G or OSFP-1600 modules
- •Aggregates multiple spine pods into a unified fabric
The bandwidth between leaf and spine layers must accommodate the all-to-all communication patterns common in distributed AI training. Insufficient spine bandwidth creates hot spots that throttle GPU utilization.
Distributed Training Interconnect Patterns
AI training frameworks use specific communication patterns that stress network infrastructure differently:
Parameter Server Architecture
- •Centralized parameter servers broadcast model updates
- •Requires high bandwidth from servers to all workers
- •QSFP-DD 800G links prevent server-side bottlenecks
Ring All-Reduce
- •Gradients circulate through a logical ring topology
- •Each node sends to one neighbor, receives from another
- •Demands consistent low-latency links between all pairs
Tree All-Reduce
- •Hierarchical aggregation of gradients
- •Matches naturally to spine-leaf network topology
- •Benefits from high-bandwidth spine-to-spine connections
Understanding these patterns helps architects provision appropriate QSFP-DD connectivity. A cluster optimized for ring all-reduce might prioritize consistent latency, while parameter server architectures need high bandwidth to specific nodes.
Real-World Deployment: 1,024 GPU Cluster
Consider the networking requirements for a mid-scale AI training cluster with 1,024 GPUs:
Physical Layout
- •32 servers × 32 GPUs each (NVIDIA DGX H100 or equivalent)
- •8 GPU servers per rack (256 GPUs per rack)
- •Total: 4 compute racks plus 2 networking racks
Leaf Switch Requirements
- •32 leaf switches (one per GPU server for optimal performance)
- •Each leaf: 32 × 400G downlinks + 8 × 800G uplinks
- •QSFP-DD modules: 1,024 × 400G SR8 + 256 × 800G DR8
Spine Switch Requirements
- •8 spine switches with 64 × 800G ports each
- •QSFP-DD modules: 512 × 800G DR8
Total QSFP-DD Count
- •1,024 × 400G SR8 modules
- •768 × 800G DR8 modules
- •Aggregate bandwidth: 820 Tb/s fabric capacity
This example illustrates why optical module procurement for AI clusters involves thousands of units, not dozens. The QSFP-DD AI data center market has grown precisely because hyperscalers deploy optics at this scale.
QSFP-DD vs OSFP: Which for AI?
When QSFP-DD Wins for AI
QSFP-DD has proven particularly advantageous in many AI data center deployments for the following reasons:
Existing QSFP28 Networks
Organizations that have invested heavily in QSFP28 infrastructure do not need to replace it overnight. The QSFP-DD port supports QSFP28 optics and allows 400G or 800G connections as needed, helping to exhaust older stock.
Heterogeneous Bandwidth
AI clusters are generally composed of mixed types of machinery. Newer systems operate at 400G/800G levels while traditional estates are limited to 100G or 200G. This creates situations where backward compatibility of the QSFP-DD format provides critical flexibility.
High Port-Density Requirements
Where rack space is limited, QSFP-DD provides up to 36 ports per 1U switch, offering higher density compared to OSFP in certain configurations. This is particularly beneficial in spine layers of the network where every port adds significant value.
Low-Power Data Centers
In environments with strict power budgets per port, QSFP-DD typically draws less power overall compared to OSFP modules. This advantage accumulates meaningfully at scale where data centers approach wattage limits.
When OSFP Wins for AI
OSFP (Octal Small Form-factor Pluggable) has its own advantages in specific AI applications:
Greenfield Clusters Built for AI Training
In new builds without legacy QSFP28 requirements, OSFP allows standardized deployment. Its larger size provides more internal space for powerful modules and easier cooling.
NVIDIA GPU Ecosystems
For 800G connections involving NVIDIA’s ConnectX-7 and ConnectX-8 NICs, the OSFP form factor has gained popularity. Enterprises heavily adopting NVIDIA products for AI workloads may find OSFP better aligns with hardware roadmaps.
Power-Hungry Coherent Optics
Coherent modules such as 800G ZR/ZR+ for DCI often exceed 20W. OSFP offers superior thermal capacity for power levels of 25W+ that can be challenging for QSFP-DD.
1.6T Migration Concerns
OSFP-XD (eXtended Density) can support up to 16 lanes for 1.6T operation. Companies planning infrastructure with a 5+ year lifespan may prefer the clearer upgrade path offered by OSFP.
Decision Matrix for AI Infrastructure
| Scenario |
Recommendation |
Rationale |
| Upgrading from 100G/200G |
QSFP-DD |
Backward compatibility protects investment |
| New NVIDIA GPU cluster |
OSFP |
Better alignment with NVIDIA roadmap |
| Mixed vendor environment |
QSFP-DD |
Broader ecosystem compatibility |
| Power-constrained deployment |
QSFP-DD LPO |
Lower power consumption |
| 800G ZR/ZR+ required |
OSFP |
Superior thermal capacity |
| 5+ year infrastructure |
OSFP |
Clearer 1.6T migration path |
| Maximum port density |
QSFP-DD |
36 vs 32 ports per 1U |
Many hyperscale operators deploy both: QSFP-DD for general-purpose compute fabrics and OSFP for dedicated AI training clusters. This hybrid approach requires careful inventory management but optimizes each workload environment.
Deployment Considerations for AI Infrastructure
Power Budget Planning
Accurate power budgeting prevents costly surprises during AI cluster deployment. Calculate total rack power including networking:
Example: 800G Leaf Switch Rack
- •8 × 32-port 800G leaf switches
- •256 × QSFP-DD800 DR8 modules @ 16W average
- •Switch ASIC power: ~400W per switch
- •Total: 256 × 16W + 8 × 400W = 7,296W
- •Cooling overhead (PUE 1.3): ~9,485W per rack
Compare this to GPU server power in the same rack. A rack with 8 DGX H100 systems draws approximately 40 kW. The networking overhead (9.5 kW) represents nearly 20% additional power requirement that must be provisioned.
Fiber Infrastructure for AI
AI clusters require massive fiber counts that strain cabling infrastructure:
MTP/MPO-16 Connectivity
800G SR8 and DR8 modules use 16 fibers (8 transmit + 8 receive). MTP-16 or dual MTP-12 connectors handle these parallel optics. Pre-terminated trunk cables with MPO-16 connectors simplify deployment but require accurate polarity management.
Fiber Type Selection
- •Intra-rack (SR8): OM4 or OM5 multimode fiber, cost-effective for short distances
- •Spine-leaf (DR8): OS2 single-mode fiber for 500m reach
- •DCI (FR4/LR4): OS2 single-mode with careful attention to loss budgets
Fiber Management at Scale
A 1,024-GPU cluster with 1,792 QSFP-DD modules requires over 28,000 fiber connections. Structured cabling with clear labeling, color-coding, and documentation becomes essential. Bend-insensitive fiber (G.657A2) helps manage tight cable routing in dense racks.
Interoperability Testing
In a multi-vendor environment where AI operates, the following things need to be validated:
Is covering compatible types of switch ASICS necessary?
Let’s make sure that the switches ASICS you aim to use support particular QSFP-DD designs. That’s because most 800G capable ASICs do not support every module type.
FEC Set Up
It is necessary to configure RS(544,514) forward error correction in 800G links for the links to perform. Make sure that all the devices along the route have the same FEC configuration.
Modular Management Using CMI
Common Management Interface Specification (CMIS) is used to manage and monitor QSFP-DD modules. CMIS 5.0 and improved versions maintain the ability to telemeter needed for AI clusters management, e.g., and monitoring the power and temperature of a device, as it happens.
Redundant Data Miss and Pass Over in a LAN (OMEM)
RoCE is the main transport of bufferless GPU computation in a number of AI clusters. Check that your QSFP-DD systems are compatible not only with Priority Flow Control for no-loss RoCE but also with Explicit Congestion Notification.
Pre-Deployment Checklist
Before committing to large-scale QSFP-DD procurement:
- •Validate switch ASIC compatibility with target module types
- •Confirm CMIS 5.0 support for management and telemetry
- •Calculate total rack-level power and thermal capacity
- •Verify fiber infrastructure (type, distance, connector compatibility)
- •Test interoperability in lab environment with actual hardware
- •Validate FEC configuration requirements
- •Review breakout cable availability for migration scenarios
- •Confirm warranty and MTBF specifications with vendor
- •Verify supply chain capacity for volume orders
Market Trends: QSFP-DD in the AI Era
2025-2026 Adoption Timeline
The optical module market is experiencing unprecedented growth driven by AI infrastructure investment:
Current State (2025)
- •800G QSFP-DD has become mainstream for new AI data center builds
- •400G serves as the baseline for general-purpose infrastructure
- •800G+ optics projected to exceed 60% of high-speed module shipments by 2026
Near-Term Outlook (2026-2027)
- •1.6T QSFP-DD and OSFP modules enter volume production
- •Co-packaged optics (CPO) emerge for ultra-high-density AI clusters
- •Linear Pluggable Optics (LPO) gain traction for power-constrained deployments
Technology Roadmap
- •2025: Majority 800G adoption
- •2026: 1.6T early deployment
- •2027: Majority 1.6T adoption for AI training clusters
- •2030: 3.2T on the horizon for next-generation AI workloads
Industry analysts project the AI optical transceiver market will reach $13.12 billion by 2032, growing at a 19.59% CAGR. This growth directly reflects the infrastructure demands of generative AI and large-scale machine learning.
Supply Chain Considerations
The significant increase in demand for AI-related products has put pressure on optical module supply chains:
Manufacturing Capacity
InnoLight, Accelink, Coherent, and others have announced expansions. AOI is setting up a 210,000 square foot facility in Texas dedicated to 800G and 1.6T products.
Chinese Vendor Ecosystem
Vendors such as Eoptolink, Hisense Broadband, and Huagong Tech have gained substantial shares in 400G and 800G module manufacturing. Due to intense price competition and manufacturing scale, they remain essential suppliers.
Planning and Lead Time
QSFP-DD orders for high-volume AI hardware clusters often experience 12-16 week lead times. To secure capacity, negotiations should begin as early as Q1 to meet Q3/Q4 deployment schedules.
Component Constraints
Global shortages of certain components have already extended lead times for CWDM4 and PSM4 transceivers beyond the standard 3-4 months. Suppliers continue to prioritize 400G and lower QSFP-DD optics as AI data center customers drive demand for higher speeds.
Conclusion
The transition to QSFP-DD for AI data centers represents more than a bandwidth upgrade—it enables the computational infrastructure powering the next generation of artificial intelligence. As AI training clusters scale from hundreds to thousands of GPUs, the optical interconnect fabric becomes the critical foundation determining overall system performance.
Key considerations for your AI networking strategy:
- •Bandwidth planning: AI workloads require 36× the fiber connectivity of traditional compute, making 400G/800G QSFP-DD essential at scale
- •Form factor selection: QSFP-DD offers backward compatibility and density for mixed environments; OSFP provides thermal headroom for greenfield AI clusters
- •Power management: 800G modules consume 14-20W each—plan rack power budgets accordingly, considering LPO variants where compatible
- •Architecture design: Spine-leaf topologies with non-blocking bandwidth between any two GPU nodes maximize training efficiency
- •Supply chain timing: Secure QSFP-DD supply early for planned deployments, as AI-driven demand strains manufacturing capacity
The infrastructure decisions you make today will determine your AI capabilities for years to come. Whether upgrading existing facilities or building new AI clusters, QSFP-DD optical transceivers provide the bandwidth density and reliability these demanding workloads require.
Ready to deploy QSFP-DD connectivity for your AI infrastructure? Contact Ascent Optics for expert guidance on module selection, compatibility verification, and deployment planning. Our engineering team specializes in high-speed optical networking for AI data centers and can help you design the optimal interconnect fabric for your specific requirements.
Frequently Asked Questions
1. Can QSFP-DD handle InfiniBand NDR connections?
Yes, 800G QSFP-DD support InfiniBand NDR (Next Data Rate) at 800 Gbps. Many AI clusters prefer InfiniBand instead of Ethernet for GPU interconnects in AI clusters, as QSFP-DD modules are built to run with both protocols, although host NICs and switches should support the specific standards.
2. How many QSFP-DD modules does an AI rack typically necessitate?
One rack with 8 GPU servers (for example, NVIDIA DGX systems) usually has 8 QSFP-DD modules for server connections and requires additional modules for switch uplinks. For a fully connected leaf switch serving, consider 8 to 16 × 800G QSFP-DD modules for spine uplinks.
3. What is the difference in latency when we compare QSFP-DD and OSFP?
At the optical layer, in both form factors, propagation delay would be the same; the medium in which the signal is transmitted (fiber) imposes a heavier penalty than the transceiver form factor. However, given OSFP’s greatly superior thermal management, one might actually observe a more consistent performance under thermal stress. If your application is delay-sensitive, you could apply an LPO without DSP processing delay.
4. Can I use the LPO QSFP-DD form factor for AI clusters?
Choose an LPO-based form factor only if you are building homogeneous AI clusters running host ASICs from a single vendor. LPO offers something like 50% of power saving in addition to ergonomically reducing latency by up to 100 ns compared to DSP-based modules. Stay away from LPOs in a multi-vendor context if the threat of interoperability issues is going to outweigh power benefits.
5. Will QSFP-DD and OSFP modules interoperate?
Yes, at the optical level, QSFP-DD and OSFP modules with the same optical specifications will interoperate with each other. For example, a QSFP-DD 800 2×FR4 can send data back to an OSFP-800 2×FR4 over some medium of fiber. The electrical interface for the host switch may be different depending on the form factor, while the optical signaling remains compatible for the same module types (SR8, DR8, FR4), etc.
Sources:
- •Cignal AI optical module forecasts
- •LightCounting market research
- •QSFP-DD MSA specifications
- •IEEE 802.3ck 800G Ethernet standard
- •Goldman Sachs AI infrastructure spending analysis
Post Views: 4,409














