Over the past decade, data centers—such as those operated by Microsoft, Alibaba Cloud, and Amazon—have expanded rapidly, with the number of servers far surpassing that of traditional supercomputers. These data centers predominantly use Ethernet for interconnection, with transmission speeds evolving from the early 10Gbps and 100Gbps to today’s 400Gbps, and are now progressing toward 800Gbps and even 1.6Tbps.
However, the growth in CPU computing power has lagged behind the increase in network bandwidth, exposing two major bottlenecks in traditional software-based network protocol stacks: first, CPUs must frequently handle network data transfers, consuming significant computing resources; second, they struggle to meet the demanding requirements for high throughput and ultra-low latency in applications such as distributed storage, big data, and machine learning.
Remote Direct Memory Access (RDMA) technology has become a key solution to this problem. Originally developed for high-performance computing (HPC), RDMA enables data to bypass the CPU and be transferred directly between server memory, significantly reducing latency and improving throughput. The widespread adoption of 400G/800G Ethernet RDMA network interface cards (NICs), such as NVIDIA ConnectX and Intel E810, has enabled large-scale deployment of RDMA in data centers.
These NICs not only support ultra-high-speed Ethernet but also enable efficient RDMA communication via protocols such as RoCE (RDMA over Converged Ethernet) or iWARP. This allows applications to fully utilize the bandwidth of 400G+ networks while reducing CPU overhead. For example, distributed storage systems (such as Ceph and NVMe-oF) and AI training frameworks (such as TensorFlow and PyTorch) have widely adopted RDMA NICs to significantly enhance data transfer efficiency.
Introduction to RDMA
Before diving into 400G Ethernet RDMA NICs, it’s important to understand what RDMA is.
RDMA (Remote Direct Memory Access) is a networking technology that enables servers to directly read from or write to the memory of other servers at high speed, without involving the operating system kernel or the CPU. Its core objectives are to reduce network communication latency, increase throughput, and significantly lower CPU resource consumption.
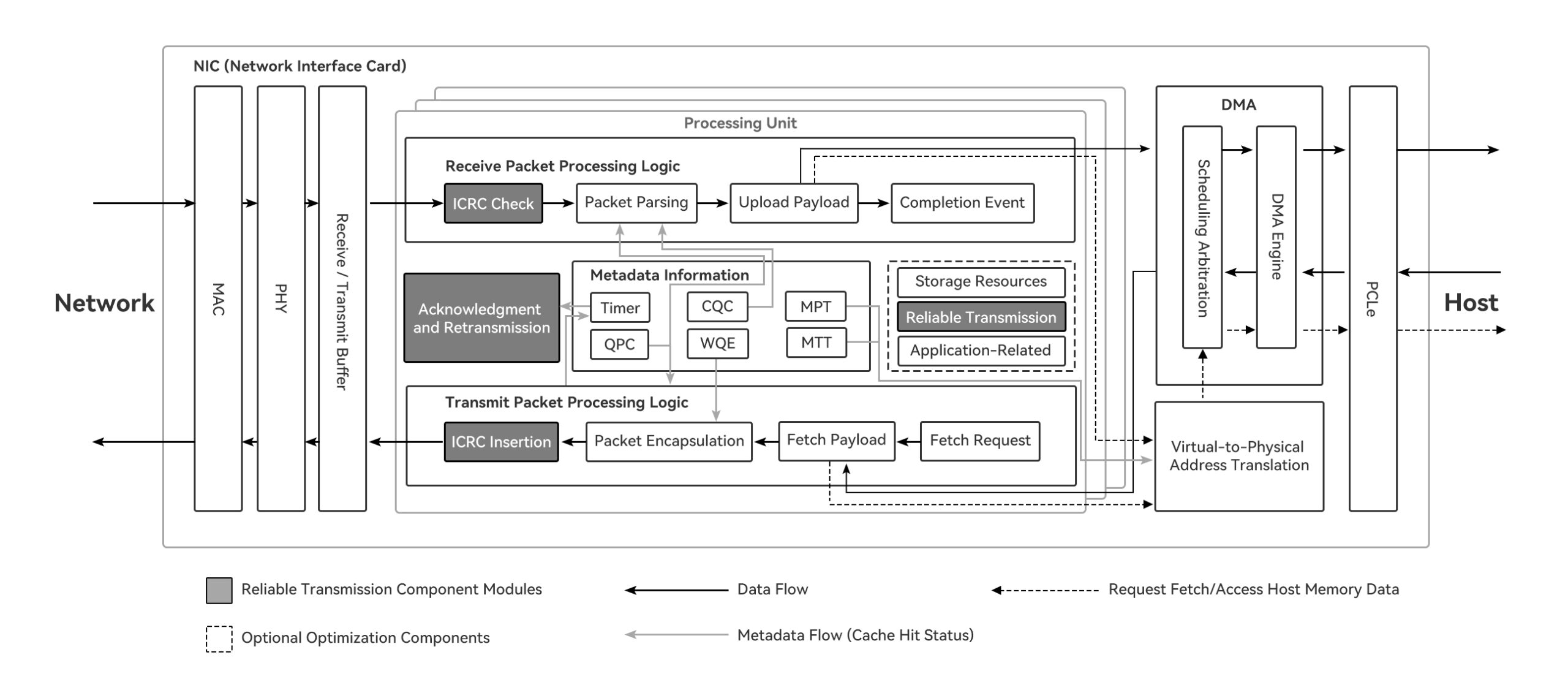
Ethernet RDMA NIC module architecture (taking transmit-receive as an example)
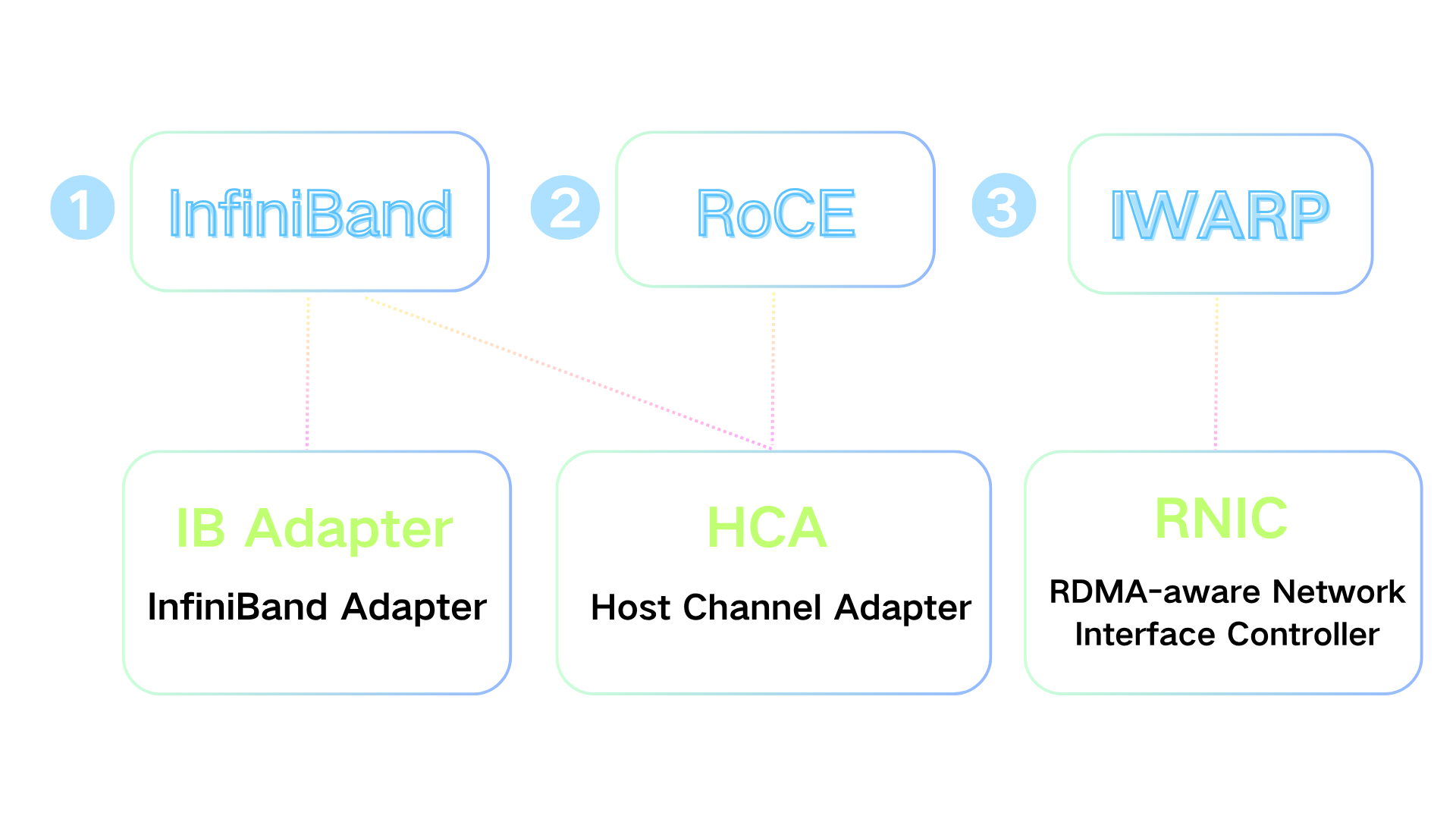
Currently, there are three mainstream implementations of RDMA: IB (InfiniBand), RoCE (RDMA over Converged Ethernet) and iWARP.
InfiniBand (IB)
Specifically designed for RDMA with hardware-level reliable transmission, offering the best performance (lowest latency).
Requires dedicated IB NICs and switches, resulting in the highest cost.
RoCE (RDMA over Converged Ethernet)
Based on Ethernet; includes RoCEv1 (Layer 2 only) and RoCEv2 (supports Layer 3 routing).
Requires lossless Ethernet (PFC/ECN) and RoCE-compatible NICs; offers high cost-performance ratio.
iWARP (Internet Wide Area RDMA Protocol)
Based on TCP/IP, compatible with standard Ethernet devices, and does not require a lossless network.
Slightly lower performance than RoCE due to TCP protocol overhead.
Core Concepts of RDMA
RDMA allows data to move directly from the memory of one computer to another, bypassing the CPU and operating system kernel. This results in:
Zero-copy data transfer: Eliminates data replication between user and kernel spaces.
Low latency: Achieves microsecond-level delays, compared to milliseconds for traditional TCP/IP.
High bandwidth: Fully utilizes network speeds up to 400Gbps or higher.
CPU offloading: Reduces CPU involvement, freeing resources for other tasks.
Supported RDMA Protocols
Two primary RDMA protocols dominate Ethernet environments:
RoCE (RDMA over Converged Ethernet):
RoCEv1: Operates at the Ethernet link layer (L2), requiring a lossless network with technologies like Data Center Bridging (DCB) and Priority Flow Control (PFC).
RoCEv2: Runs over UDP/IP (L3), enabling routing across subnets while still needing Quality of Service (QoS) mechanisms like DCQCN (Data Center Quantized Congestion Notification).
iWARP (Internet Wide Area RDMA Protocol):
Built on TCP/IP, it integrates with existing Ethernet infrastructure but incurs slightly higher latency and CPU overhead compared to RoCE. It is better suited for wide-area networks.
Image source: Cloud Computing Popular Science Research Institute
Ethernet RDMA NICs are high-performance network hardware that allow a computer to directly access the memory of a remote host without involving the CPU. This significantly reduces latency, increases throughput, and lowers CPU overhead.
As Ethernet RDMA technology gains widespread attention and deployment in data center scenarios such as network storage and cloud computing, Ethernet RDMA NICs—being the key components for enabling this technology—are playing an increasingly vital role.
On one hand, the NIC is responsible for implementing the most complex aspects of Ethernet RDMA technology, such as protocol offloading, reliable transmission, and congestion control. In contrast, switches typically require only relatively simple functionalities, such as priority-based flow control (PFC) and explicit congestion notification (ECN).
On the other hand, offloading processing to hardware means the NIC must store state information needed for reading and writing remote memory. However, the on-chip cache and processing logic resources of the NIC are limited, making it essential to have a solid understanding of the NIC’s microarchitecture for effective design and optimization.
400G Ethernet RDMA Network Cards: The Core Engine of Next-Generation High-Performance Networking
400G Ethernet RDMA network cards represent a pinnacle of high-performance networking technology, designed to meet the escalating demands of modern data centers, high-performance computing (HPC), and cloud environments. By enabling direct memory access between systems without CPU intervention, these cards deliver ultra-low latency, high throughput, and significant CPU offloading. This article explores the core features, applications, technical details, and future trends of 400G Ethernet RDMA network cards.
RDMA Support: Enables zero-copy, kernel-bypass data transfer via RoCEv2 (UDP/IP-based) or iWARP (TCP/IP-based).
Hardware Offload:
Protocol stack offload (e.g., RoCEv2’s UDP/IP or iWARP’s TCP/IP).
Packet checksum, segmentation/reassembly, and congestion control (e.g., DCQCN) handled by the NIC.
Low Latency: End-to-end latency can be as low as <1 μs (depending on network configuration).
Multi-Protocol Compatibility: Typically supports Ethernet (400G), InfiniBand (e.g., NVIDIA ConnectX-7), and storage protocols (e.g., NVMe-oF).
Major Vendors and Products
Leading vendors provide advanced 400G RDMA solutions:
NVIDIA: ConnectX-7 series supports RoCEv2 and InfiniBand, with PCIe 4.0/5.0 and GPUDirect RDMA for AI workloads.
Intel: Ethernet 800 series (e.g., E810) supports iWARP and RoCEv2, integrating with Infrastructure Processing Units (IPUs).
Broadcom: BCM58800 series offers 400G RoCEv2 with Stingray SmartNIC capabilities.
Marvell: OCTEON 10 DPU provides 400G RDMA with data-plane offloading for encryption and compression.
NVIDIA 400G ConnectX-7 InfiniBand Adapter Card
Application Scenarios of 400G Ethernet RDMA Network Cards
400G Ethernet RDMA network cards are primarily used in network environments that require high bandwidth and low latency, such as high-performance computing (HPC), artificial intelligence (AI), big data analytics, and cloud computing. Below are some specific application scenarios:
High-Performance Computing (HPC):
Scientific Computing: Used in fields like astronomy, meteorology, and fluid dynamics for simulations and calculations.
Supercomputers: Connects supercomputer clusters to enable efficient inter-node communication.
Artificial Intelligence (AI) and Machine Learning (ML):
Deep Learning Training: Connects GPU clusters to accelerate data transfer during model training.
Distributed Inference: Efficiently transmits inference tasks and results between multiple AI servers.
Big Data Analytics:
Real-Time Data Processing: Supports real-time analytics and processing on big data platforms.
Data Warehousing: Enables efficient loading and querying of large-scale data warehouse contents.
Cloud Computing:
Cloud Storage: Enables high-speed data transfer and access in cloud storage systems.
Virtualized Environments: Facilitates efficient memory access and data transfer between virtual machines.
Storage Networks:
Distributed Storage: Provides efficient metadata synchronization and data transfer in distributed storage systems.
Object Storage: Delivers high-speed data access and transmission in object storage environments.
Network Function Virtualization (NFV):
Virtual Network Functions (VNF): Enables efficient data transmission and communication between VNFs.
Financial Trading:
High-Frequency Trading: Delivers ultra-low latency for data transmission and processing in financial trading systems.
Telecommunication Networks:
5G Core Network: Supports efficient data transport and control in 5G core network infrastructures.
All these application scenarios demand high-bandwidth, low-latency network connections. With their high performance and low latency, 400G Ethernet RDMA network cards can significantly enhance the performance and efficiency of these applications.
Technical Challenges and Solutions
Challenge 1: Network Congestion Control
Issue: 400G traffic bursts can easily cause packet loss, and RoCEv2 is highly sensitive to packet loss.
Solutions:
Enable DCQCN (Data Center Quantized Congestion Notification) or TIMELY (latency-based congestion control).
Configure lossless Ethernet using PFC + ECN, while avoiding Head-of-Line (HOL) blocking caused by PFC.
Challenge 2: CPU/PCIe Bottleneck
Issue: 400G line rate requires PCIe 4.0 x16 or PCIe 5.0 x8 bandwidth (~64GB/s).
Solutions:
Use PCIe 5.0 slots (32GT/s per lane).
Optimize with multi-queue configuration, binding each CPU core to an independent queue.
Challenge 3: Thermal and Power Management
Issue: 400G NICs can consume 25–40W, requiring robust cooling.
Solutions:
Choose NICs with heat sinks or active cooling fans.
Optimize chassis airflow design.
Market Trends: The Future of RDMA and 400G Ethernet
As data center networks rapidly evolve from 100G/200G toward 400G and beyond, Ethernet RDMA network cards are becoming core components of next-generation high-performance infrastructure. The following trends highlight the current trajectory and future direction of the RDMA ecosystem:
While InfiniBand has long been the gold standard for high-performance communication, its proprietary nature and high cost have limited large-scale adoption. In contrast, RoCEv2, an open and Ethernet-based RDMA solution, offers a compelling alternative due to its performance, affordability, and ecosystem maturity.
Hyperscale cloud providers such as AWS, Alibaba Cloud, and Microsoft Azure are increasingly integrating RoCEv2 into their infrastructures to accelerate AI training, storage access, and multi-tenant computing efficiency.
Cost Efficiency: RoCEv2 vs. InfiniBand
Lower Deployment Costs: RoCEv2 runs on standard Ethernet hardware, enabling reuse of existing switches and cabling infrastructure.
Simplified Operations: Ethernet is well understood and easier to maintain for most engineering teams.
Better Scalability: RoCEv2 supports Layer 3 routing, making it suitable for large-scale, multi-rack, and cross-subnet deployments.
These attributes make RoCEv2 a high-performance yet cost-effective choice for modern data centers.
Future Evolution
(1) 800G/1.6T Ethernet Is on the Horizon
Driven by innovations in switching silicon (e.g., Broadcom Tomahawk 5) and PHY standards, the industry is preparing for 800G and 1.6T Ethernet adoption. Next-generation RDMA NICs—such as NVIDIA’s upcoming ConnectX-8—will support higher port densities, lower power consumption, and increased throughput, further enhancing RDMA’s role in scalable computing infrastructures.
Data Processing Units (DPUs) represent the next step in smart networking, combining traditional NIC capabilities with programmable compute. By embedding RDMA functionality into DPUs, these devices can offload network, storage, and security processing from the CPU—enabling end-to-end acceleration for AI workloads and disaggregated storage.
For example, NVIDIA’s BlueField DPU integrates RDMA, IPsec, and NVMe-oF acceleration, and is becoming a key component of next-gen hyperconverged infrastructure.
(3) SmartNIC Intelligence: In-Network Computing
SmartNICs are evolving from simple data movers to programmable in-network compute nodes with features like:
Data Aggregation & Preprocessing: Perform real-time flow aggregation or filtering at the NIC level to reduce CPU workload.
Encryption & Compression Offload: Execute secure data transformations before traffic exits the server.
AI Inference Assistance: Some high-end SmartNICs include onboard AI engines for edge-side inference and decision-making.
This trend transforms RDMA NICs into intelligent execution engines for distributed systems, far beyond traditional network acceleration.
Conclusion
400G Ethernet RDMA network cards are transformative for data centers, HPC, and AI-driven applications. By leveraging hardware offloading, RoCEv2 or iWARP protocols, and advanced congestion control, these cards deliver unparalleled performance with minimal latency and CPU overhead. Careful attention to network configuration, PCIe bandwidth, and thermal design is critical for optimal deployment. As the industry moves toward 800G and DPU-integrated solutions, RDMA technology will continue to redefine the boundaries of distributed computing and storage performance.