NVIDIA Dynamo: An Efficient Distributed Inference Framework for Large AI Models
September 16, 2025
With the development of large language models (LLMs) and generative AI technologies, efficiently deploying and serving these models has become a major challenge for the industry. Traditional inference service frameworks often face issues such as insufficient GPU utilization, memory bottlenecks, and inefficient data transfer when handling large-scale distributed environments. The emergence of NVIDIA Dynamo provides an innovative solution to these challenges.
NVIDIA Dynamo is an open-source, high-throughput, low-latency inference framework designed specifically for serving generative AI and inference models, including large language models (LLMs), in multi-node distributed environments. It addresses the challenges of AI inference scaling by efficiently coordinating across multiple GPUs and servers, ensuring performance comparable to a single accelerator while managing tensor parallelism, KV cache management, and data transfer.
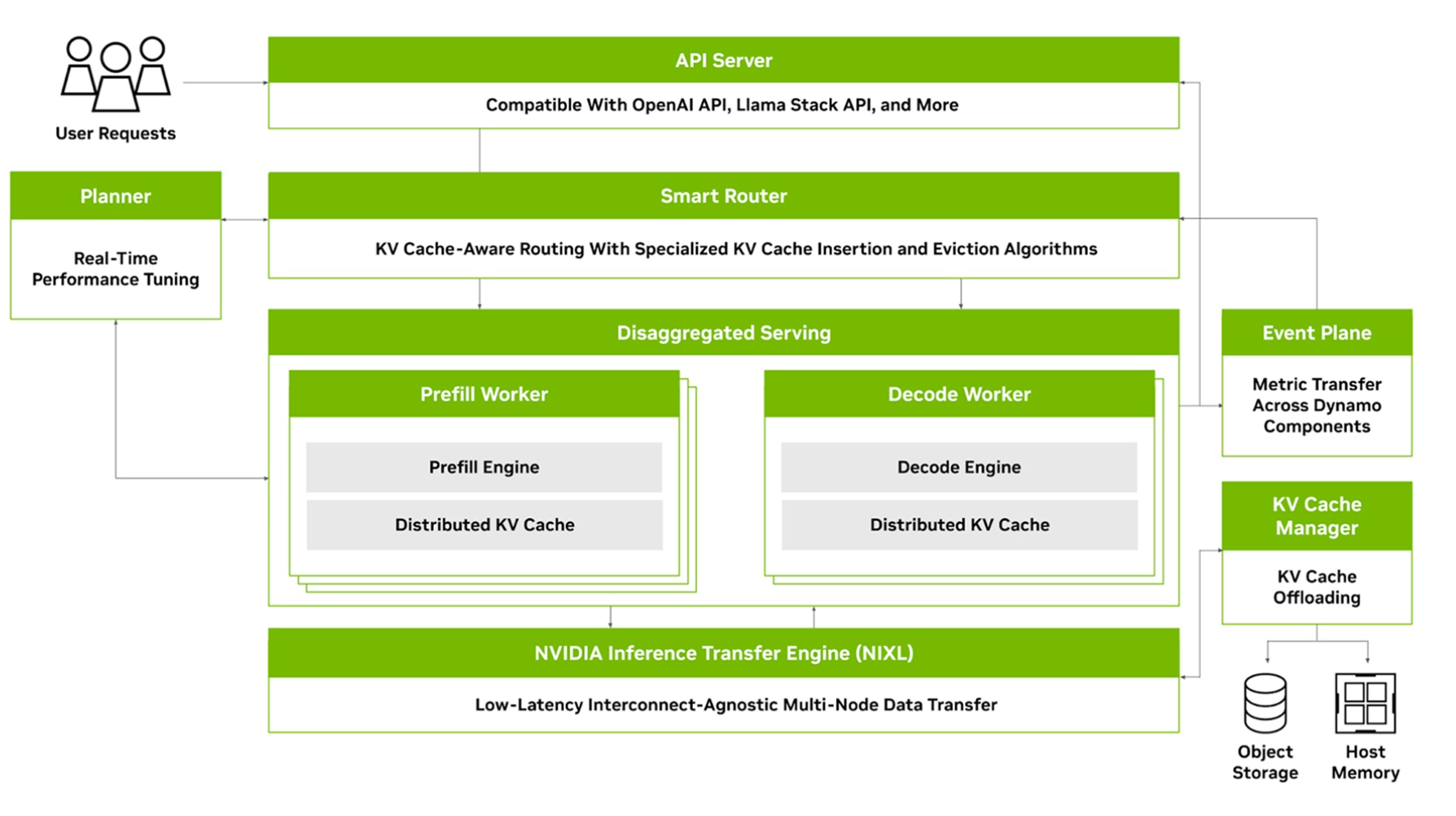
Dynamo is not just an inference framework but a comprehensive distributed inference ecosystem. By separating the prefill and decoding phases, implementing KV-aware routing, and optimizing memory management, it significantly enhances inference performance and resource utilization.
It is primarily built with the Rust language (55.5%), while integrating Go (28.5%) and Python (9.3%), ensuring a perfect combination of high performance and ease of extensibility.
Low-Latency Communication Library: Accelerates KV cache transfer between GPUs, supporting heterogeneous memory and storage types.
KV Cache Manager: Cost-aware KV cache offloading engine that frees up precious GPU memory, delivering core advantages.
These features make Dynamo particularly suitable for AI factories, scalable AI agents, code generation, and inference tasks, while reducing total cost of ownership (TCO) through better resource utilization.
Dynamo Core Components
Core Features
Dynamo’s design philosophy focuses on tackling the biggest hurdles in distributed AI inference services. Its key features include:
Inference Engine Independence
Dynamo works seamlessly with various inference engines like TRT-LLM, vLLM, and SGLang, giving users plenty of flexibility to pick what suits them best. Build once, deploy anywhere—this eliminates the headaches of mismatched tech stacks.
Separated Prefill and Decode
This is one of Dynamo’s standout innovations. It splits LLM requests into two dedicated phases—prefill (initial processing) and decode (ongoing generation)—running on specialized engines. This maximizes GPU usage, lets you easily balance speed (throughput) and quick responses (latency), and fixes bottlenecks in computing power.
Dynamic GPU Scheduling
It smartly adjusts GPU resources in real-time based on changing workloads, preventing waste and slowdowns. This handles uneven loads head-on, boosting GPU efficiency big time.
NIXL for Faster Data Transfer
A custom communication protocol tuned just for AI tasks, it slashes response times during inference and cuts down on the communication delays that plague distributed setups.
Multi-Level KV Cache Management
By smartly spreading the KV cache (key-value storage for faster AI responses) across different memory layers—like GPU, CPU, SSD, or even cloud object storage—it makes the most of every bit of memory. This ramps up your service capacity and smashes through memory limitations.
As a next-generation distributed inference service framework, Dynamo has achieved significant breakthroughs across multiple technical dimensions.
Architectural Innovation: Through a decoupled service design, Dynamo successfully resolves the issue of uneven resource utilization between the prefill and decoding stages in traditional monolithic inference pipelines. This design not only enhances GPU utilization but also provides specialized, optimized execution environments for different types of workloads.
Intelligent Routing: The introduction of KV-aware routing algorithms enables the system to intelligently avoid redundant computations, significantly improving inference efficiency. This routing strategy is particularly suitable for handling request scenarios with similar prefixes, and can deliver substantial performance improvements in practical applications.
Memory Management Optimization: The multi-layer memory architecture and intelligent cache management strategies allow the system to handle large-scale models that exceed single-GPU memory limits while maintaining high performance. The use of radix tree indexing further enhances the efficiency of cache queries.
Network Transmission Optimization: The integration of the NIXL transmission library provides specialized optimized data transmission capabilities for distributed inference scenarios. This optimization is particularly crucial for decoupled service architectures, as it can significantly reduce the latency of KV cache transmissions.
Application Scenarios
Dynamo is suitable for the following application scenarios:
Large-scale production environments: For production environments that need to handle a large number of concurrent requests, Dynamo’s distributed architecture and intelligent routing can provide stable and reliable services.
Multi-model services: The system supports multiple inference engines, capable of serving different types of models simultaneously, providing a unified inference platform for diverse AI applications.
Resource-constrained environments: Through multi-layer memory management and cache optimization, the system can provide high-quality inference services under limited hardware resources.
Latency-sensitive applications: KV-aware routing and cache optimization are particularly suitable for real-time applications with strict requirements on response latency.
In summary, NVIDIA Dynamo, through the deep integration of intelligent routing, optimized memory management, and network transmission enhancements, not only addresses the core challenges of distributed inference services but also provides an efficient and scalable solution for large-scale AI deployments. As an open-source framework, Dynamo will continue to drive innovation and application of generative AI technologies, helping enterprises and developers achieve higher performance and cost efficiency in resource-constrained environments. Looking ahead, as the AI ecosystem continues to evolve, Dynamo is expected to become an industry standard, accelerating the adoption and widespread implementation of intelligent applications.