Among the foundational elements of network architecture, interconnect technology is undoubtedly one of the most critical components. In modern data centers, the explosive growth of AI is placing unprecedented pressure on this fundamental technology. Without efficient interconnects, even the most advanced AI models will suffer from performance bottlenecks and stalls.
AI Reshaping Network Demands: The Four Major Challenges Facing Interconnect Technologies
The unique characteristics of AI workloads are fundamentally rewriting the design logic of data center interconnect technologies. Traditional network architectures were built for general-purpose computing scenarios and struggle to adapt to the special requirements of AI. Whether in terms of data transfer patterns, bandwidth scale, or latency sensitivity, AI scenarios far exceed the boundaries of traditional data center applications, pushing interconnect technologies to the very limits of their original designs.
To understand these challenges, we first need to compare the core differences between AI workloads and traditional workloads:

This difference directly translates into the four major pain points of interconnect technologies: How to support the high-density interactions of all-to-all communication? How to cope with the non-linear growth of bandwidth demands? How to compress latency down to sub-microsecond levels? And how to sustain continuous high traffic pressure? These are precisely the core directions that current AI data center interconnect technologies must break through.
The Evolution Path of the Three Major Interconnect Technologies: Ethernet, InfiniBand, and Omni-Path
Faced with the challenges brought by AI, by 2025 the data center interconnect field has formed three mainstream technical routes: Ethernet, InfiniBand, and Omni-Path.
Rooted in different technical DNA, and through continuous iteration and optimization, these three technologies have developed differentiated competitive advantages in compatibility, performance, and cost respectively.
-
Ethernet: From General-Purpose to AI-Optimized, Breaking Through to Terabit-Class Speeds
As a mature standard with decades of history, Ethernet has long dominated enterprise data centers thanks to its strong compatibility, controllable costs, and excellent scalability.
However, in AI scenarios, traditional Ethernet reveals clear weaknesses: under high traffic loads it is prone to increased latency and packet loss, making it difficult to meet the stringent stability requirements of all-to-all communication patterns.
To adapt to AI, Ethernet has achieved a complete transformation through two key technological upgrades:
(1) IEEE 802.3df-2024: 800GbE Establishes the Foundation for Next-Generation AI Clusters
The IEEE 802.3df-2024 standard, released in February 2024, can be regarded as a watershed moment for AI data center interconnects. This 800GbE specification not only delivers massive bandwidth capacity, but also introduces an 8-lane parallel architecture that enables highly flexible port breakout configurations. A single 800GbE port can be flexibly split — depending on workload requirements — into: 2 × 400GbE, 4 × 200GbE or 8 × 100GbE.
This capability perfectly matches the hybrid traffic patterns typical in AI training: some accelerators require extremely high-bandwidth peer-to-peer interaction, while others only need lower-bandwidth synchronization.
(2) UEC 1.0: Ethernet’s Dedicated AI Optimization Solution
In 2025, the Ultra Ethernet Consortium (UEC) — jointly initiated by industry heavyweights — released the UEC 1.0 specification. This represents the most aggressive optimization effort ever made to adapt Ethernet specifically for AI workloads. The specification directly targets InfiniBand’s performance advantages through three core technical innovations:
Modern RDMA Deployment
Introduces RDMA (Remote Direct Memory Access) technology, enabling GPUs to directly access the memory of other devices without CPU involvement, dramatically reducing latency.
Link-Level Retry (LLR)
Addresses Ethernet’s long-standing historical weakness of packet loss. Instead of relying on traditional Priority-based Flow Control (PFC), LLR performs loss detection and retransmission directly at the link layer — eliminating the high recovery cost that would otherwise fall on higher-layer protocols.
Packet Rate Improvement (PRI)
Reduces protocol overhead through header compression while adding network probe functionality for real-time congestion visibility. This allows administrators to dynamically adjust traffic distribution based on actual conditions.
In addition, UEC 1.0 introduces support for switch-side packet spraying + NIC-side reordering — a mechanism previously seen only in proprietary systems. This capability now enables standard Ethernet to effectively handle the intense all-to-all communication pressure characteristic of large-scale AI training workloads.
2. InfiniBand: From High Performance to 800Gb/s, Solidifying Its Low-Latency Advantage
InfiniBand was born in the late 1990s. From the very beginning of its design, it targeted high-speed server-to-server communication within data centers. Unlike Ethernet, which evolved from local area network (LAN) origins, InfiniBand was purpose-built from the ground up to meet the stringent demands of cluster computing.
Its core strengths lie in lossless transmission and ultra-low latency. Through hardware-level flow control and dedicated network adapters, InfiniBand directly addresses one of the most critical pain points in AI training: the cascading failures and stalls caused by packet loss.
(1) Credit-Based Flow Control: The Performance Cornerstone of InfiniBand
The fundamental difference between InfiniBand and Ethernet lies in InfiniBand’s credit-based flow control mechanism. Before transmitting packets, the sender first verifies that the receiver has sufficient buffer space, preventing packet loss at the source. This design is critical for AI training: in large-scale training clusters involving thousands of accelerators, the loss of even a single packet can force an entire batch to be recomputed. Credit-based flow control effectively eliminates this risk.
(2) XDR Evolution: Sustaining Low Latency at 800 Gb/s Bandwidth
In October 2023, the InfiniBand Trade Association (IBTA) released the InfiniBand Specification Version 1.7, ushering InfiniBand into the XDR (Extended Data Rate) era. This upgrade increases single-port bandwidth to 800 Gb/s, while inter-switch link speeds reach up to 1.6 Tb/s, enabled by 200 Gb/s per-lane SerDes technology.
3. Omni-Path: From Dormancy to Revival, Targeting Cost-Sensitive AI Scenarios
Omni-Path has had a notably dramatic journey. Originally introduced by Intel in the mid-2010s, it was designed to challenge NVIDIA InfiniBand’s dominance in the HPC market. With features such as adaptive routing, integrated fabric management, and competitive performance, Omni-Path once attracted significant industry attention. However, in 2019, Intel announced the discontinuation of the Omni-Path project to refocus on its core processor business, and the technology subsequently fell into dormancy.
In 2020, Omni-Path saw a turning point when the original Intel Omni-Path engineering team spun off to form Cornelis Networks. The company revived development of the technology and launched the CN5000 series, positioning it as a cost-competitive AI interconnect solution.
Current Positioning: Cost Optimization at 400 Gb/s
Cornelis Networks’ strategy is very clear: rather than competing head-to-head with InfiniBand on absolute performance, it targets price-sensitive AI deployment scenarios—such as LLM fine-tuning in small and mid-sized enterprises and edge AI training—by offering a 400 Gb/s interconnect solution that delivers sufficient performance at a lower cost. Its core competitive advantage lies in meeting the needs of medium-scale AI training while reducing both hardware and operational costs by approximately 20–30% compared with NVIDIA InfiniBand solutions, according to publicly released data from Cornelis.
Future Direction: Dual-Mode Compatibility to Break Ecosystem Barriers
The biggest challenge facing Omni-Path is the well-established vendor ecosystems and software optimization stacks built around Ethernet and InfiniBand. To address this, Cornelis plans to introduce dual-mode support in its next-generation CN6000 series, enabling operation with both the native Omni-Path protocol and Ethernet. This approach aims to alleviate users’ concerns about migration by improving ecosystem compatibility. However, whether this strategy will succeed will largely depend on subsequent progress in software enablement—such as integration with PyTorch and TensorFlow—as well as partnerships with other vendors.
Three Technologies Side-by-Side Comparison: Performance, Cost, and Scenario Fit
To more clearly understand the differences among the three technologies, we conduct a side-by-side comparison across key dimensions including core parameters, advantages, and more:
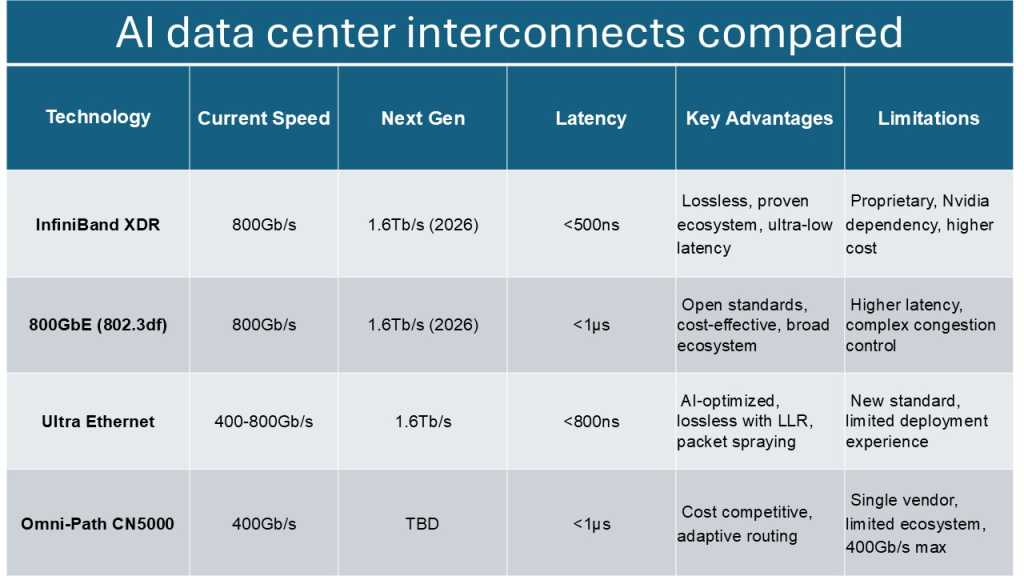
Interconnect Technologies: The Invisible Infrastructure of the AI Era
As AI reshapes industries across the board, data center interconnect technologies are evolving from behind-the-scenes data pipelines into front-line intelligent architectures. In the current landscape, InfiniBand—thanks to its irreplaceable low-latency advantages—remains the performance benchmark for hyperscale AI training. Ethernet, strengthened by advancements such as UEC and IEEE 802.3df, has become the pragmatic choice for most enterprises due to its open ecosystem and broad compatibility. Meanwhile, the revival of Omni-Path offers the industry a third option focused on cost optimization.
Looking ahead, the future of data center interconnects is unlikely to be dominated by a single technology. Instead, hybrid architectures are emerging as the prevailing trend. Hyperscalers such as Google and AWS have already begun adopting mixed approaches—using InfiniBand for core training workloads while relying on Ethernet for edge inference and traditional applications—to strike a balance between performance and cost. Just as AI intelligence arises from the connections between neurons, the AI capabilities of data centers may ultimately depend on the evolution of interconnect technologies, which will continue to provide the foundational momentum for AI breakthroughs.
Post Views: 3,587






