As AI computing scales toward tens-of-thousands-GPU clusters, interconnect technology has become a core bottleneck limiting performance, directly determining the efficiency of AI training and inference. Based on recent presentations released by the Open Compute Project (OCP), this article provides a comprehensive analysis of three mainstream interconnect technologies—Ultra Accelerator Link (UAL), Ethernet-based UALoE/SUE (UAL over Ethernet), and RoCE (RDMA over Converged Ethernet)—examining their key characteristics, performance differences, and applicable scenarios to evaluate how each solution fits large-scale AI deployments.
Technology Foundation
The performance differences among AI interconnect technologies fundamentally stem from their underlying architectural design principles. Memory-semantic–driven UAL and Ethernet-ecosystem–compatible derivatives (including UALoE/SUE and RoCE) differ significantly in their base design logic and architectural implementation. These differences directly determine their behavior in key metrics such as load balancing, latency control, and bandwidth utilization:
UAL: A dedicated, AI-optimized memory-semantic interconnect designed to achieve ultra-low latency and maximum efficiency.
UALoE / SUE: Combines memory semantics with Ethernet headers, striking a balance between performance and ecosystem compatibility.
RoCE: An RDMA-based Ethernet technology that leverages a mature ecosystem and focuses on high-throughput, bulk data transfer scenarios.

UAL
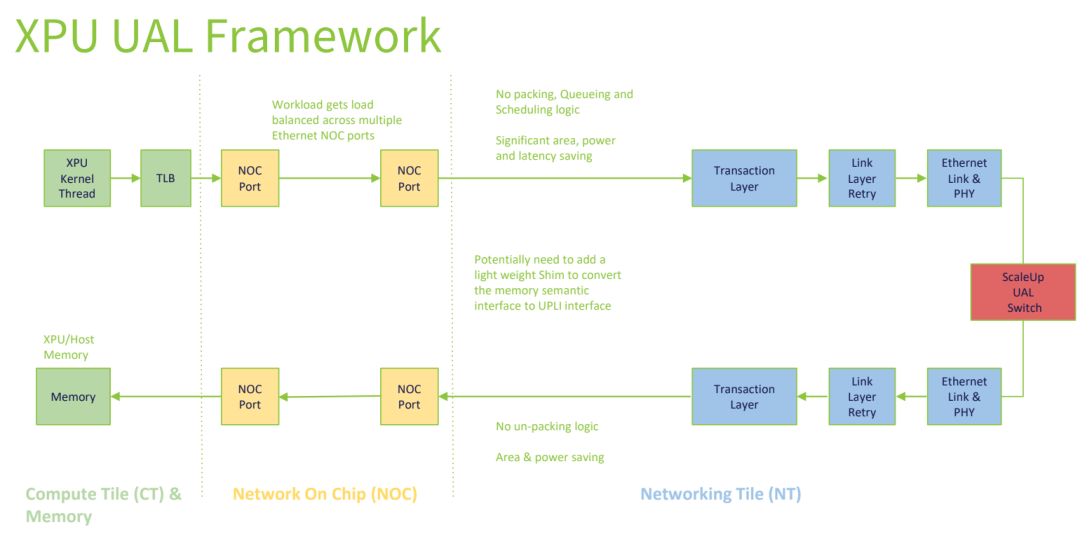
UAL is a memory-semantic interconnect technology specifically designed for AI scale-out architectures, with the core objective of eliminating redundant overhead in data transmission. Its key design features include:
No Ethernet dependency: Data is transmitted directly based on memory semantics without Ethernet encapsulation, reducing protocol-layer overhead.
No packetization/depacketization logic: Uses a fixed 640-byte flit design, eliminating the need to aggregate transactions into packets and significantly reducing hardware area, power consumption, and latency.
No RTT latency: Employs a compute-layer push model—DMA engines are deployed within Compute Tiles (CTs) and directly initiate inter-XPU data transfers without waiting for Network Tiles (NTs) to pull data, thereby avoiding round-trip latency.
High load-balancing efficiency: Based on 256-byte transaction–level fine-grained balancing, ensuring optimal lane utilization across all transfer sizes (256B–4096B). This is especially well suited for small-batch, high-frequency AI traffic.
High fault tolerance: Supports multi-lane port degradation, maintaining up to 50% bandwidth even in the event of a single-lane failure, ensuring uninterrupted workloads.
In addition, UAL requires only the potential addition of a lightweight shim (adaptation layer) to convert the memory-semantic interface into a UPLI interface, simplifying hardware integration.
UALoE/SUE
UALoE/SUE is a compromise solution designed for compatibility with the Ethernet ecosystem. Its core approach is to encapsulate an optimized Ethernet header in memory-semantic transmissions, preserving the high efficiency of UAL while enabling seamless integration into existing Ethernet infrastructure.
Key Features:
Inheritance of UAL’s High-Efficiency Genes: It retains UAL’s 256B transaction-level load balancing and compute-layer Push model. For small transfers (256B–512B), bandwidth efficiency is close to that of pure UAL, with zero RTT (round-trip time) latency.
Optimized Ethernet Header: Uses a streamlined 14B Ethernet header combined with an 8B request + 4B response (total overhead of 26B). This is significantly lower than traditional Ethernet’s redundant designs, minimizing the performance penalty from compatibility requirements.
On-Demand Packet Aggregation Mechanism: The sender and receiver must aggregate small transactions into larger packets for transmission (e.g., 512B and above). While this introduces some packing overhead, bandwidth can match UAL levels for ≥512B transfers. If the Ethernet inter-frame gap (IPG) is further reduced from 20B, the performance gap can be completely eliminated.
Native Ecosystem Compatibility: Directly compatible with existing Ethernet switches and NICs, requiring no major reconstruction of cluster networks. This greatly reduces upgrade costs for enterprises, making it especially suitable for AI clusters already built on Ethernet infrastructure.
In summary, UALoE/SUE (where UALoE likely stands for “UAL over Ethernet” and SUE refers to Broadcom’s Scale-Up Ethernet) represents a practical bridge between proprietary high-performance protocols (like UALink/UAL) and the widely deployed Ethernet ecosystem. It targets scale-up AI networking, balancing near-native efficiency for memory operations with broad interoperability and lower deployment barriers. This makes it an attractive option for AI/HPC environments transitioning toward standardized, cost-effective interconnects.
RoCE
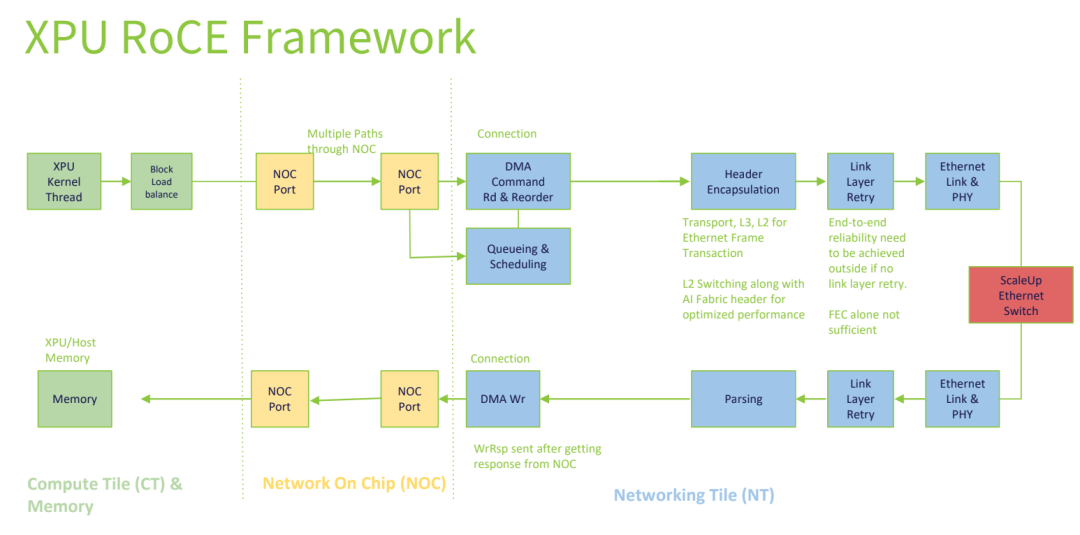
RoCE (RDMA over Converged Ethernet) is an Ethernet-based interconnection solution built on RDMA technology. It leverages a mature RDMA ecosystem and excels in bulk data transfer scenarios, but it has clear shortcomings in AI small-packet (small transfer) workloads.
Key Limitations:
Block-Level Load Balancing: RoCE employs block-level data distribution, which is only suitable for bulk transfers of ≥2048B. For small-sized transfers (<1024B), it easily leads to channel imbalance, resulting in bandwidth utilization below 50%.
Network-Layer Pull Model: DMA threads are deployed in the Network Tile (NT), requiring data to be pulled from the Compute Tile (CT). This introduces a fixed startup overhead of 240ns + a base processing latency of 440ns. Additionally, reordering jitter (~400ns) increases with packet size.
Reliability Dependent on ACK/NACK: It relies on Selective ACK/NACK mechanisms to ensure transmission reliability. Without link-layer retry support, higher-layer mechanisms are needed to compensate, leading to high complexity in fault handling (e.g., requiring connection remapping).
In summary, while RoCE provides excellent performance for large-scale, high-throughput data movements in traditional HPC and storage applications (thanks to low CPU involvement and high bandwidth), its design—rooted in block-oriented handling, pull-based initiation from the network side, and dependency on selective acknowledgments—makes it less efficient for the frequent, small-message communications typical in modern AI training workloads (e.g., gradient synchronization in distributed models). This has driven interest in newer alternatives like UALink, Ultra Ethernet, or optimized Ethernet variants (e.g., UALoE/SUE) that better address small-packet efficiency, push models, and reduced overhead for AI/HPC scale-up scenarios.
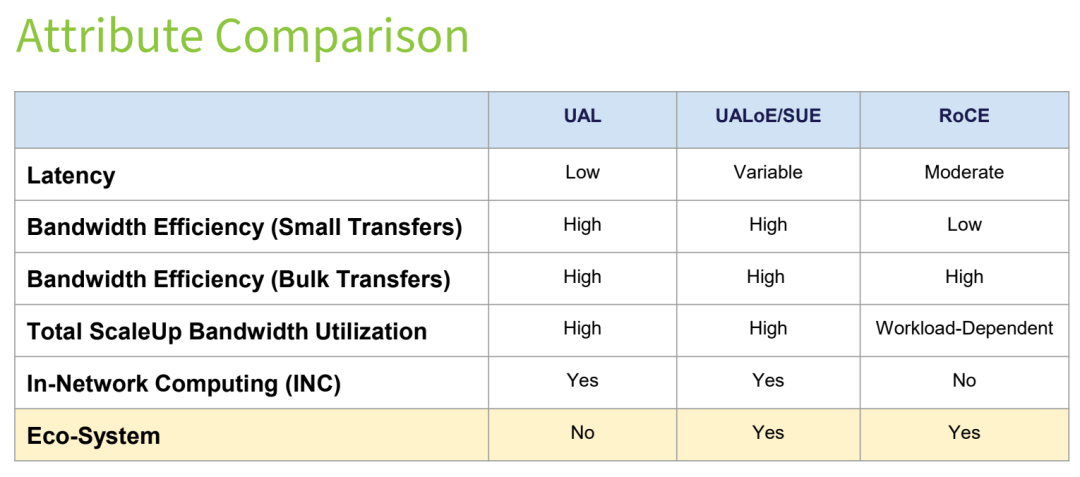
The report conducts a quantitative comparison of the three technologies across three major dimensions: workflow, functionality, and attributes. The core differences are summarized in the tables below.
Table 1: Workflow Differences Comparison
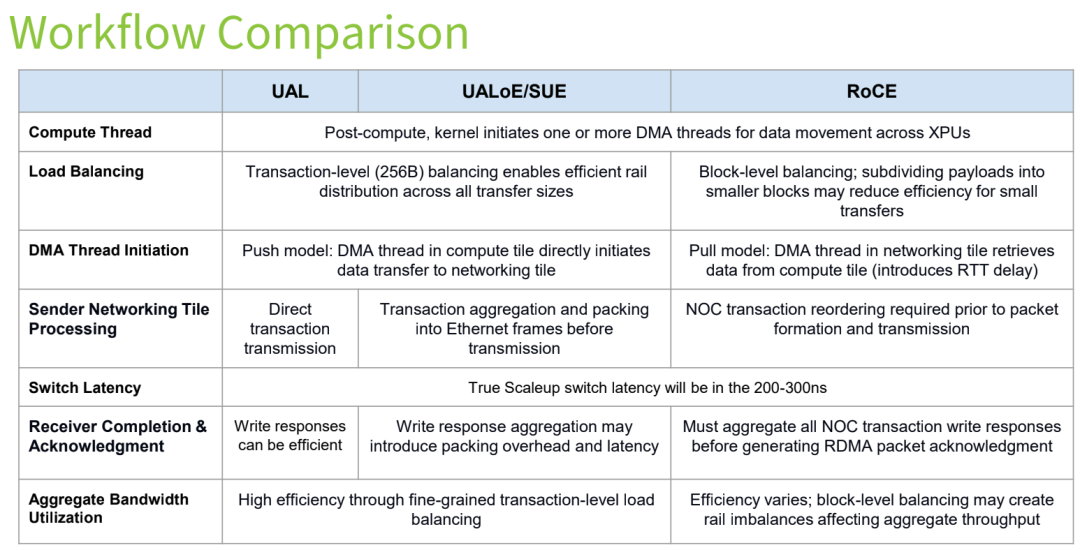
Table 2: Functionality Differences Comparison
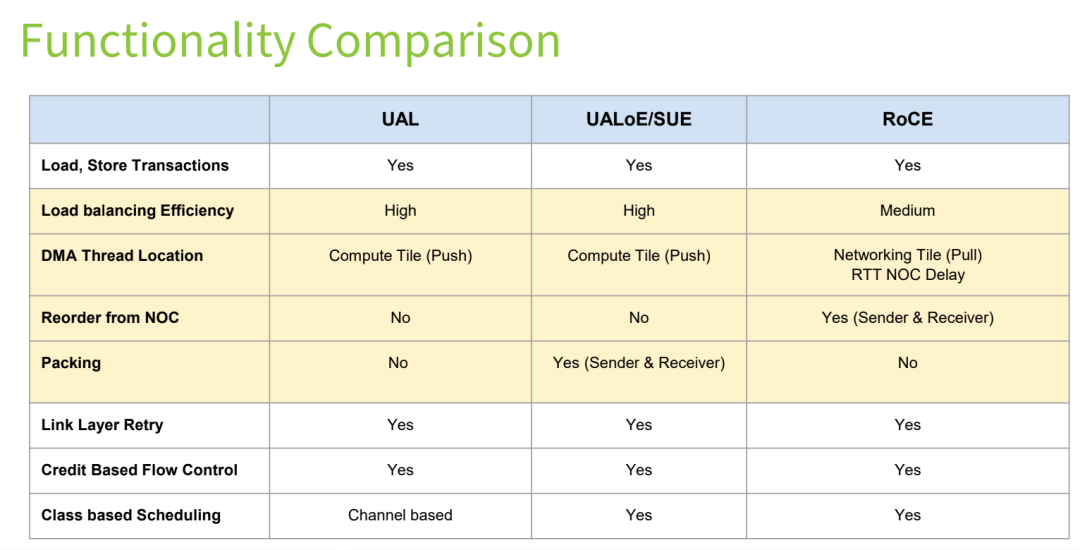
Table 3: Attributes Differences Comparison
Performance Benchmarking
Bandwidth Efficiency: Packet Size Determines the Efficiency Ceiling
The core bottleneck of bandwidth efficiency lies in header overhead and packet aggregation strategy. The three technologies exhibit significant performance differences under varying packet sizes:

UAL: Maintains optimal efficiency across all scenarios.
With no additional headers whatsoever, UAL achieves near-theoretical-maximum bandwidth efficiency for both small 256-byte packets and large multi-KB packets. There is virtually no efficiency loss caused by excessive header overhead.
UALoE/SUE: Efficiency varies dynamically with packet size.
In small-packet scenarios (below 256 bytes), the 14-byte Ethernet header takes up a disproportionately large portion, resulting in bandwidth efficiency of only 60%–70% of pure UAL.
When packet size increases to 512–768 bytes, aggregation of multiple memory transactions helps amortize the header overhead, raising efficiency to approximately 90% of UAL — but it can never fully match UAL’s performance.
RoCE: Starts with the lowest efficiency and has a limited ceiling.
In small-packet scenarios, the combination of multi-layer headers and ACK overhead drives efficiency below 50% of UAL.
Even when MTU (Maximum Transmission Unit) is set to the maximum value, the continuous overhead introduced by the ACK mechanism keeps peak efficiency noticeably lower than both UAL and UALoE/SUE.
Latency Performance: A Stark Contrast in Determinism and Jitter
Latency is a critical metric for large-scale AI training (e.g., parameter exchange/synchronization) and real-time inference. The three technologies exhibit clearly distinct latency characteristics:
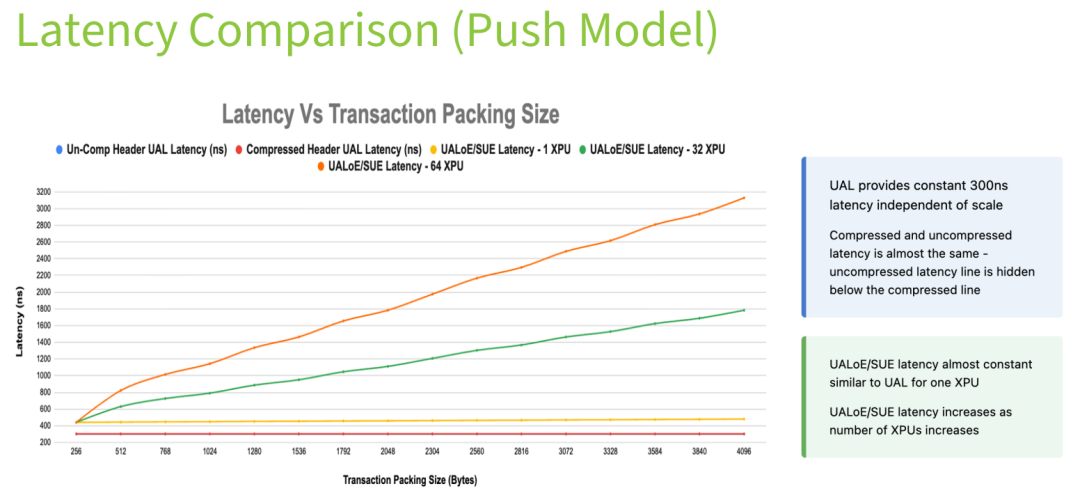
UAL: Lowest latency with zero jitter.
It delivers a fixed latency of only 300 nanoseconds (200 ns in the switch + 100 ns at the accelerator side). Regardless of the number of connections or packet sizes, latency remains perfectly stable — fully meeting the stringent low-latency requirements of demanding AI workloads.
UALoE/SUE: Higher latency with noticeable jitter.
Baseline latency is 400 nanoseconds (including 100 ns of packing overhead). When the number of concurrent connections increases to 32 or more, deeper packet aggregation is required to improve bandwidth efficiency, causing latency to rise above 500 nanoseconds. Jitter can reach up to 100 nanoseconds.
RoCE: Highest latency with strong uncertainty.
Baseline latency exceeds 600 nanoseconds, and as transaction size grows, additional variable delays are introduced from data pull operations, reordering, ACK waiting, and other stages. Jitter can reach microsecond levels, making it difficult to satisfy the strict latency stability demands of modern AI scenarios.
In short:
UAL offers the best-in-class deterministic, ultra-low latency — ideal for latency-sensitive AI/HPC workloads.
UALoE/SUE represents a practical trade-off: slightly higher and less stable latency in exchange for Ethernet compatibility.
RoCE suffers the most in both average latency and jitter, especially under the small, frequent message patterns typical of AI training.
Technology Selection
Based on the performance comparison results, the applicable boundaries of the three technologies are clearly defined.
UAL: Best suited for latency-sensitive, bandwidth-intensive core workloads, such as gradient exchange in tens-of-thousands-GPU AI training and data transfer in real-time inference. It is particularly ideal for ultra-large-scale AI clusters that pursue maximum performance.
UALoE / SUE: Appropriate for scenarios that require compatibility with existing Ethernet infrastructure and have lower latency sensitivity, such as non-real-time AI inference, data backup, and data migration. It serves as a transitional solution between UAL and the Ethernet ecosystem.
RoCE: Recommended for general-purpose RDMA use cases in traditional data centers. In large-scale AI computing environments, it is best suited only for non–performance-critical auxiliary data transfers.
Conclusion
As AI compute capability continues to scale rapidly, interconnect technology has evolved from a supporting component into a core competitive differentiator. With its ultra-low latency and high bandwidth efficiency, UAL is poised to become a mainstream choice for future ultra-large-scale AI clusters, while ongoing optimization of UALoE/SUE and RoCE will provide greater flexibility across diverse infrastructure environments. Looking ahead, continued protocol standardization and architectural innovation will further unlock AI computing potential and drive large-scale AI applications to the next level of maturity.
Post Views: 1,723






