
In 2025, the rapid development of artificial intelligence (AI) is reshaping data center architectures. From multimodal large language models to open and efficient frameworks, AI has become the core driving force of innovation. The scale of AI models is expanding from hundreds of millions of parameters to the trillion level, with training involving thousands or even tens of thousands of GPUs in parallel. For example, OpenAI’s GPT-4o and similar models require real-time data synchronization to enable efficient inference and training. This not only demands data throughput at the TB/s level, but also microsecond-level latency and high reliability to eliminate any bottlenecks.
Against this backdrop, traditional 100G/200G network interconnects can no longer meet the requirements. 400G/800G OSFP optical modules provide a more compact and efficient interconnection solution, while DAC (Direct Attach Cable) and AOC (Active Optical Cable) are the preferred options for short-reach connections, effectively optimizing cost and power consumption. AI is no longer just about algorithmic innovation, but a system-level engineering effort deeply integrated with physical infrastructure.

The AI landscape in 2025 is defined by versatility and open-source innovation. Several leading models highlight how these advancements are reshaping interconnect demands:
GPT-4o (OpenAI)
Renowned for its strong multimodal processing capabilities across text, image, and speech, GPT-4o relies on synchronized training across thousands of GPUs. Each GPU requires data exchange at hundreds of GB/s, and any interconnect bottleneck can significantly prolong training time.
Claude 3.7 Sonnet (Anthropic)
Specialized in coding and complex reasoning tasks, Claude 3.7 Sonnet requires real-time data streams to sustain efficient inference. Ultra-low-latency interconnects are essential, with 800G optical modules enabling energy efficiency at approximately 5 pJ/bit.
Gemini 2.5 (Google)
Excelling in multimodal inference and scientific research applications, Gemini 2.5 emphasizes high bandwidth and large-scale distributed communication. Its performance depends heavily on DWDM systems and high-speed Ethernet interconnects.
Grok 3/4 (xAI)
With built-in voice mode and efficient inference capabilities, Grok 3/4 is typically deployed in GB200 clusters. Each GPU requires an 800GbE interface to achieve doubled performance.
Llama 3 / DeepSeek V3 (Meta / DeepSeek)
As leading representatives of open-source models, Llama 3 and DeepSeek V3 emphasize high performance and customizability. Their distributed training depends on 400G/800G interconnects, boosting overall efficiency by 20–25%.
| AI Model | Developer | Key Features | Compute & Interconnect Requirements |
| GPT-4o | OpenAI | Multimodal (text, image, speech); advanced reasoning; supports o1/o3 variants | Requires large-scale GPU cluster synchronization, with per-GPU data exchange reaching hundreds of GB/s during training; interconnect bottlenecks can extend training time by 2–3×. |
| Claude 3.7 Sonnet | Anthropic | Strong at coding and complex tasks; cost-efficient | Inference relies on real-time data streaming, demanding ultra-low-latency interconnects to support concurrent queries; 800G optics can reduce energy cost to ~5 pJ/bit. |
| Gemini 2.5 | Efficient multimodal processing; optimized for developers and research | Training emphasizes parallel computing, with interconnect requirements focused on high bandwidth to handle DWDM (Dense Wavelength Division Multiplexing) multi-wavelength transmission. | |
| Grok 3/4 | xAI | Efficient inference, voice-mode support, open-source friendly | Typically deployed in large-scale clusters (e.g., GB200), where each GPU requires 800GbE connectivity to achieve 2× performance scaling. |
| Llama 3 / DeepSeek V3 | Meta / DeepSeek | Open-source, high-performance, customizable training | Distributed training depends on cross-node communication, with 400G/800G interconnects boosting overall efficiency by ~25%. |
These models share a common characteristic: they rely on Mixture of Experts (MoE) or similar architectures, which require frequent All-to-All communication. Training ultra-large models like GPT-4o may involve petabyte-level data exchanges, and insufficient interconnects can drive network costs up by more than 70%.
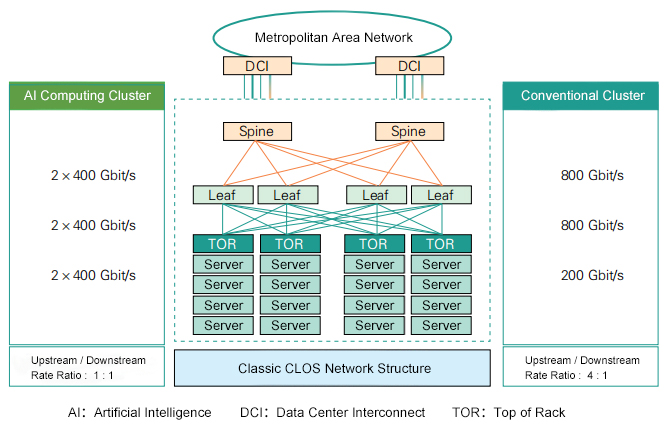
At the core of AI training and inference lies the synchronization of massive GPU clusters. For example, in an NVIDIA GB200 cluster, each GPU requires 800GbE (2×400GbE) connectivity to support PCIe Gen6 direct communication, avoiding CPU bottlenecks. The main challenges include:
1. OSFP Optical Modules
The Optical Small Form-factor Pluggable (OSFP) supports 400G/800G speeds and leverages silicon photonics (SiPh) or EML modulators. In AI deployments, OSFP modules are used for long-reach transmission (>100m), enabling up to 4 Tbps bidirectional connectivity. For example, Intel’s OCI chipsets utilize DWDM to achieve low power consumption (~5 pJ/bit).
2. DAC (Direct Attach Cable)
A copper-based solution designed for short-reach (<7m) in-rack connections, DAC offers a cost-effective option without requiring optical-electrical conversion. In AI clusters, solutions such as the AMD Pensando Pollara 400 NIC employ DACs to deliver 400Gbps bandwidth while supporting RDMA (Remote Direct Memory Access) to accelerate data transfers.
3. AOC (Active Optical Cable)
Featuring integrated optical transceivers, AOCs are suited for medium-reach (7–100m) connections. They provide higher reliability and help avoid port contamination. In AI environments, AOCs are widely used for parallel cabling, supporting 800G data center deployments.
In practical applications, these technologies directly enhance AI performance:
Training phase: For example, in the distributed training of Llama 3, 400G SR4 modules are used to ensure low-latency communication between GPUs, improving utilization.
Inference phase: Gemini 2.5’s real-time processing relies on 800G AOC to achieve 3200 Gbps data transfer.
Case study: OpenAI’s Stargate cluster uses custom 800GbE NICs, with each GPU equipped with 8× OSFP ports, delivering 2× network performance. AMD’s Vulcano NIC provides 800 Gbps throughput and supports the UC 1.0 standard.
Open source and scalability: For instance, DeepSeek V3 leverages RDMA to optimize interconnects, reducing bridging costs.
In practical deployments, these interconnect technologies are often used in combination: DAC and AOC are best suited for short-reach connections within or between adjacent racks, delivering low cost, low latency, and simplified cabling at scale. OSFP optical modules, on the other hand, are primarily deployed for inter-rack or even inter-data hall connections, offering higher bandwidth, stability, and scalability over longer distances. This layered approach allows data centers to balance cost, power consumption, and performance, thereby supporting the training and inference demands of large-scale AI clusters.
In summary, the integration of high-speed interconnect technologies with advanced AI models is shaping the next era of data center innovation. Combining the latest AI models with 400G/800G interconnects not only demonstrates technological synergy but also highlights the critical role of infrastructure in the AI ecosystem. Interconnect technology is not merely an enabler of artificial intelligence—it is the cornerstone of its future development.
















